Robotics
DAM-VLA: A Dynamic Action Model-Based Vision-Language-Action Framework for Robot Manipulation
1 Introduction

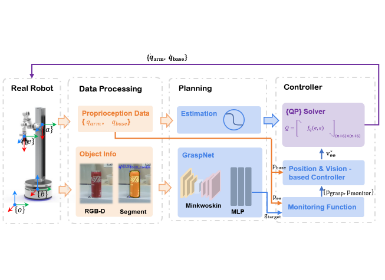
Figure 1. DAM-VLA framework and experimental results
A central challenge in robotics is enabling robots to perform diverse tasks in dynamic environments. Conventional robot learning methods typically train policies on datasets curated for a specific robot and task. The resulting policies act as specialists, such as the popular ACT [1] and Diffusion Policy [2]. Although these approaches achieve high precision in targeted scenarios, they generalize poorly across varying environments and tasks.
Recently, VLA models have attracted attention for their ability to extend pretrained VLMs to robotics by discretizing continuous actions into bins for action prediction. Representative works such as RT-2 [3] and OpenVLA [4] have demonstrated impressive performance in multi-task learning and generalization. By enabling robots to interpret visual observations and language instructions, VLA models can generate generalizable action sequences. Consequently, leveraging the inherent capabilities of VLMs in developing VLA frameworks is crucial for achieving both task-specific precision and broad generalization in dynamic environments.
To better leverage the inherent capabilities of VLMs for VLA models that combine both task-specific and general manipulation in dynamic environments, we first identify several key distinctions between arm movement and gripper manipulation. In many robotic tasks, arm movement spans a larger spatial range than gripper manipulation. Consequently, arm trajectories often dominate the scene in the observed images, while gripper manipulations are confined to small, localized regions. Figure 2 illustrates this disparity using the task of placing a carrot on a plate as an example, where arm movement requires global attention, whereas gripper manipulation demands localized focus. Specifically, we identify three distinctions between the arm movement and the gripper manipulation using the task of placing a carrot on a plate as an illustrative example: Path Constrains, Visual Attention, and Dataset Representation.

Figure 2. Tree distinctions between the arm movement and the gripper manipulation
Building on these distinctions, we leverage VLM reasoning to differentiate action types (arm movement vs. gripper manipulation), and apply the corresponding action model to perform the required manipulation. Rather than loosely coupling a VLM with separate action models, we introduce the DAM-VLA framework (Figure 1), which fully exploits the strengths of VLMs to support both task-specific precision and generalization in dynamic environments. The main contributions of this work are summarized as follows: (1) Action Routing. A VLM-guided router interprets task-specific visual and linguistic cues to select the appropriate action models (e.g., arm movement or gripper manipulation). (2) Dynamic Action Model. A dual-head diffusion model that integrates high-level cognition from the VLM with low-level visual information to predict actions across different models. (3) Dual-Scale Action Weighting. A two-scale weighting mechanism (i.e., trajectory-level and action-chunk-level) enables dynamic coordination between the arm-movement and gripper-manipulation models. (4) Extensive Evaluation. DAM-VLA achieves superior average success rates compared to state-of-the-art VLA methods, across both pick-and-place tasks in the SIMPLER simulation and long-horizon tasks in the FurnitureBench simulation, as well as in real-world pick-and-place experiments.
2 Method
Our goal is to develop a dynamic action model-based VLA framework that enables different robots to physically execute diverse tasks in dynamic environments while receiving an RGB image observation and a task description in the form of a language instruction. Formally, given the language instruction $l$ and visual observation $o_t$ at time $t$, the model $π$ predicts a temporal action sequence $[a_t,a_{t+1},…,a_{t+N}]= π(l,o_t)$. The action space $a_t= [∆x,∆θ,s^{grip}]$ corresponds to the gripper with 7 degrees of freedom (DoF), where $∆x$ represents the relative translation offsets of the end effector, $∆θ$ denotes the rotational changes, and $s^{grip}∈\{0,1\}$ indicates the gripper’s open or close state.

Figure 3. The architecture of our DAM-VLA
In Figure 3, the architecture of DAM-VLA is shown to consist of three key components: 1) A vision-language model, that encodes information from observation $o_t$ into visual tokens $f^{vis}$, a class token $f^{cls}$, and a register token $f^{reg}$, and integrates visual tokens $f^{vis}$ with a set of linguistic tokens $f^{lan}$ from a language instruction $l$, and produces the cognition latent $f^{cog}$ and reasoning latent $f^{rea}$; 2) An action routing module that generates a weight $w and feeds it into the dynamic action model; 3) A dynamic action model that dynamically executes different action models by combining the low-level class token $f^{cls}$ or register token $f^{reg}$ from the vision model with the high-level cognition latent $f^{cog}$ from the VLM to predict an action sequence $[a_t,a_{t+1},…,a_{t+N}]$.
3 Results
We conduct extensive experiments to comprehensively evaluate the performance of our proposed method and to clearly demonstrate its effectiveness in both task-specific and general-purpose manipulation scenarios. Specifically, we present the experimental results on SIMPLER in Section Simulated Evaluations. We also conduct real-world evaluations based on a pick-and-place task and present the results in Section Real-world Evaluations.
3.1 Simulated Evaluations
We first evaluate our method using the SIMPLER simulation. SIMPLER supports two robot embodiments: the Google robot and the WidowX robot. For the Google robot, evaluations are conducted under both Visual Matching (VM) and Variant Aggregation (VA) settings across four tasks, whereas the WidowX robot is evaluated only under the VM setting. The VM setting closely replicates real-world tasks by minimizing discrepancies between simulated and real-world environments. In contrast, the VA setting extends the VM setting by introducing variations in factors such as background, lighting, distractors, and table texture. The success rate of task completion is used as the evaluation metric for all VLA models. Notably, we follow CogACT in determining the number of trials conducted in SIMPLER.
Table 1 compares our method against existing VLA approaches on the Google robot across four tasks. Our model leads with average success rates of 83% (VM) and 81% (VA). Notably, we see substantial gains in the "Open Drawer and Place Apple" task, which requires task-specific manipulation. Moreover, in the VA setting, our success rate markedly exceeds competitors, demonstrating DAM-VLA mitigates performance degradation in dynamic environments. Table 1 also reports the success rates of our method compared with existing VLA approaches on the WidowX robot in SIMPLER across four tasks under the VM setting. Our model achieves the highest average success rate of 71%, outperforming competing methods by a substantial margin. In particular, DAM-VLA shows notable improvements in the Put Spoon on Towel and Put Carrot on Plate tasks, which involve more diverse object pose variations.

Table 1. Comparison of success rates between our method and existing VLA methods on the Google robot and WidowX robot in both Variant Aggregation (VA) and Visual Matching (VM) settings of the SIMPLER simulated evaluation. (PCC: Pick Coke Can; MN: Move Near; OCD: Open/Close Drawer; ODPA: Open Drawer and Place Apple; SoT: Put Spoon on Towel; CoP: Put Carrot on Plater; GoY: Stack Green Block on Yellow Block; EiB: Put Eggplant in Yellow Basket.)
3.2 Real-world Evaluations
Our real-world dataset is collected under diverse object placements and lighting conditions. To assess robustness, we divide the evaluation into in-distribution and out-of-distribution scenarios, as illustrated in Table 2. The in-distribution scenario includes variations in object positions and lighting that are consistent with the training distribution. In contrast, the out-of-distribution scenario introduces previously unseen backgrounds, novel objects, and visual distractors that are absent during training. Table 2 also reports the success rates of DAM-VLA compared with CogACT [5] on the real-world pick-and-place task. The results demonstrate that DAM-VLA consistently outperforms CogACT, achieving higher success rates in both evaluation settings.

Table 2. The success rates of our method compared with CogACT on the pick-and-place task in the real-world evaluation. ID: In-Distribution, OOD: Out-of-Distribution
4 Conclusion
Our method dynamically integrates the inherent reasoning capabilities of VLMs with specialized diffusion-based action models designed for arm movement and gripper manipulation. Extensive experiments demonstrate that our approach not only significantly outperforms existing VLA methods but also delivers stable results in both task-specific and general manipulation scenarios within dynamic environments. By dynamically routing between specialized action models based on VLM-guided cues, DAM-VLA paves a new path for incorporating semantic understanding into embodied decision-making. Its demonstrated generalization ability and stability across diverse tasks and dynamic settings highlight its potential as a foundational framework for next-generation adaptable robotic systems.
References
[1] T. Z. Zhao, V. Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” arXiv preprint arXiv:2304.13705, 2023.
[2] C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” The International Journal of Robotics Research, p.02783649241273668, 2023.
[3] A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn et al., “Rt-2: Visionlanguage-action models transfer web knowledge to robotic control,” arXiv preprint arXiv:2307.15818, 2023.
[4] M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi et al., “Openvla: An open-source vision-language-action model,” arXiv preprint arXiv:2406.09246, 2024.
[5] Q. Li, Y. Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y. Deng, S. Xu, Y. Zhang et al., “Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation,” arXiv preprint arXiv:2411.19650, 2024.