Robotics
RAMP: Hierarchical Reactive Motion Planning for Manipulation Tasks Using Implicit Signed Distance Functions
Introduction

Figure 1. RAMP Execution. Motivated by table clearing scenarios that require picking, leftover disposal and placing, we present a reactive motion planning architecture (RAMP) which can ensure safety against obstacles and provides fast, real-time trajectory updates.
Despite numerous advances in motion planning, existing solutions for high degree-of-freedom robots struggle to provide fast and reliable solutions in unknown environments. In particular, the cost of collision checking can be prohibitive for real-time applications. Further, there is no well-established trade-off between global path optimality and local reactivity to dynamic obstacles or unexpected conditions.
Current planning approaches can be divided into two major categories: reactive and non-reactive. Traditional reactive schemes, such as artificial potential fields [1] or navigation functions [2], generally provide fast updates and guaranteed safety against obstacles. However, their limitations due to local minima or numerical stability issues are well-documented [3]. Additionally, purely reactive schemes typically need implicit representations of obstacles, which are not easy to obtain in high-dimensional configuration spaces.
On the other hand, various non-reactive, primarily sampling-based algorithms such as Probabilistic Road Map (PRM) or Rapidly-exploring Random Trees (RRT) [3] have enjoyed wide adoption due to their general applicability. However, such approaches typically optimize for a trajectory using a full explicit map of the environment and might need to plan from scratch when that map changes, resulting in slow and inefficient implementations that cannot easily adapt to environments explored online. In addition, the sequential manner in which these algorithms expand during planning makes parallelization and GPU acceleration a difficult task.
Model Predictive Control (MPC) schemes provide a middle ground between pure reactive control and open-loop sampling-based planning: they can account for obstacles incrementally and quickly adjust the resulting trajectory. Moreover, MPC schemes that rely on forward simulation of control inputs, such as Model Predictive Path Integral (MPPI) control [4], are parallelizable and can be implemented on a GPU. However, their proposed control trajectories can drastically change between timesteps, producing jerky inputs which require post-processing (e.g., control input spline fitting). Unlike traditional planning methods, MPC schemes simply encode task completion, safety or other configuration constraints as cost functions in the optimization problem, which are not guaranteed to be satisfied by the resulting trajectory.
This work proposes Reactive Action and Motion Planner (RAMP), a hierarchical reactive scheme for high-dimensional robot manipulators (Figure. 1). In the proposed approach, a fast MPPI-based trajectory generator guides a local vector field-based trajectory follower, which generates real-time safe and smooth motions while satisfying constraints. Our approach is the first one to use an implicit Signed Distance Function (SDF) module for reactive control, computed directly using the robot’s configuration. The ability to parallelize direct distance queries on the GPU enables our approach to run in real-time.
Method and System Architecture
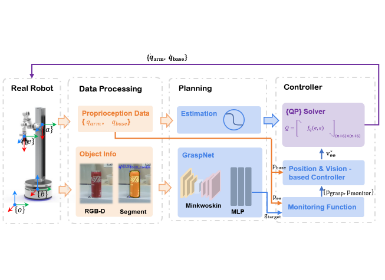
Our motion planning architecture is summarized in Figure. 2. It consists of two distinct modules running in parallel and communicating asynchronously: an MPPI-based trajectory generator and a vector field-based trajectory follower. Given a target configuration  , the input to the trajectory generator is the current robot configuration
, the input to the trajectory generator is the current robot configuration  at each control iteration, and the output is a proposed trajectory in the configuration space, as a sequence of
at each control iteration, and the output is a proposed trajectory in the configuration space, as a sequence of  waypoints
waypoints  , connecting
, connecting  and
and  (i.e.,
(i.e.,  and
and  ). The trajectory follower tracks the most recent proposed trajectory from the trajectory generator and avoids obstacles in real-time, by generating velocity commands
). The trajectory follower tracks the most recent proposed trajectory from the trajectory generator and avoids obstacles in real-time, by generating velocity commands  in the tangent space of the robot’s configuration space. The trajectory generator asynchronously updates the proposed trajectory for the follower after each MPPI iteration.
in the tangent space of the robot’s configuration space. The trajectory generator asynchronously updates the proposed trajectory for the follower after each MPPI iteration.

Figure 2. Overview of the RAMP motion planning architecture. Assuming a known target joint configuration, the inputs to the system are the current joint configuration and the current point cloud scene representation, and the output is a desired velocity command. Our algorithm consists of two modules running in parallel and communicating asynchronously: an MPPI-based trajectory generator proposes trajectories to a vector field-based trajectory follower, which tracks the most recently proposed trajectory and avoids obstacles in real-time. Both modules use a Configuration Signed Distance Function (C-SDF) module, either for estimating collision costs of proposed configurations during planning (trajectory generator), or for avoiding obstacles by moving along the positive direction of the C-SDF gradient as needed (trajectory follower).
Both modules use estimates of the robot body’s signed distance to the scene point cloud given its joint configuration. We refer to these values as the Configuration Signed Distance Function (C-SDF) values. The trajectory generator uses C-SDF values to estimate the collision cost of proposed states during planning, whereas the trajectory follower uses the C-SDF value and gradient with respect to the current configuration in order to avoid obstacles. With GPU acceleration, we can afford to use an accurate C-SDF estimation algorithm, based on direct computation of distances between the scene and some pre-defined control points on the robot’s body.
A. Configuration Signed Distance Function
Given a batch of 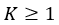 robot configurations
robot configurations 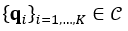 , the first step in rapidly estimating their C-SDF values is to generate control points that roughly represent the robot’s placement in the workspace. To this end, we pick a set of
, the first step in rapidly estimating their C-SDF values is to generate control points that roughly represent the robot’s placement in the workspace. To this end, we pick a set of  skeleton link frames which coincide with some of the robot’s joints, so that their pose in the workspace given a specific robot configuration can be easily computed using GPU-accelerated forward kinematics [5]. Then, we linearly interpolate between the locations of those frames to get a set of
skeleton link frames which coincide with some of the robot’s joints, so that their pose in the workspace given a specific robot configuration can be easily computed using GPU-accelerated forward kinematics [5]. Then, we linearly interpolate between the locations of those frames to get a set of  control points
control points  for each configuration
for each configuration  .
.
After the computation of the control points, we proceed to define an SDF representation in the robot’s workspace. Namely, given a representation of the scene as a dense point cloud with  points
points  we write the SDF value of a point
we write the SDF value of a point  as
as

with  a small value that ensures the existence of both positive and negative SDF values and, therefore, the smoothness of the SDF zero level set. Given this SDF representation, defined over the robot’s workspace, and a configuration
a small value that ensures the existence of both positive and negative SDF values and, therefore, the smoothness of the SDF zero level set. Given this SDF representation, defined over the robot’s workspace, and a configuration  with corresponding control points
with corresponding control points  we write the C-SDF of , conditioned on the
we write the C-SDF of , conditioned on the  control points as
control points as

with  a safety threshold. A positive C-SDF value implies that the robot is not in collision with the environment and vice versa. Using GPU acceleration, in our experiments we typically perform distance queries between hundreds of control points and thousands of points in the scene point cloud in less than 5ms.
a safety threshold. A positive C-SDF value implies that the robot is not in collision with the environment and vice versa. Using GPU acceleration, in our experiments we typically perform distance queries between hundreds of control points and thousands of points in the scene point cloud in less than 5ms.
B. Trajectory Generation
Using the C-SDF module, at each MPC step, our trajectory generator constructs a proposed trajectory in the configuration space, connecting the current configuration and a target configuration , by configuring MPPI [4] as a trajectory planner that samples multiple trajectories in parallel, computes their associated costs, and combines them by exponential averaging. For each sampled trajectory, we penalize its total length and final distance from the goal, as well as collisions with the environment and self-collisions at each horizon step.
Our MPPI model is given as a discrete-time, continuous-state system  , where
, where  , with
, with  a nominal (prior) displacement from
a nominal (prior) displacement from  at time
at time  and
and  its covariance. In our implementation, we initialize the MPPI loop with the hypothesis that the start and goal configurations are connected by a straight line path in joint space. We discretize this path to find intermediate waypoints and the associated (nominal) displacements, which we use to start our MPPI updates. After each MPPI step, we update the trajectory tracked by the follower with the new configuration rollout.
its covariance. In our implementation, we initialize the MPPI loop with the hypothesis that the start and goal configurations are connected by a straight line path in joint space. We discretize this path to find intermediate waypoints and the associated (nominal) displacements, which we use to start our MPPI updates. After each MPPI step, we update the trajectory tracked by the follower with the new configuration rollout.
C. Trajectory Following
Finally, our trajectory follower tracks the most recent proposed trajectory from the trajectory generator and avoids obstacles in real-time, by generating velocity commands  in the configuration space. To this end, each time the trajectory generator provides a new trajectory, we generate an arclength parameterization
in the configuration space. To this end, each time the trajectory generator provides a new trajectory, we generate an arclength parameterization  , such that
, such that  and
and  .
.
During execution, given the current robot configuration we first compute its C-SDF value,  . By construction of the C-SDF, a sphere centered at any of the robot’s control points at configuration with radius equal to
. By construction of the C-SDF, a sphere centered at any of the robot’s control points at configuration with radius equal to  is collision-free. Hence, inspired by [6], we pick as target
is collision-free. Hence, inspired by [6], we pick as target 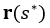 at configuration the furthest point along the trajectory with control points at most
at configuration the furthest point along the trajectory with control points at most  away from the control points at . This immediately implies that is also safe. Formally, we write
away from the control points at . This immediately implies that is also safe. Formally, we write

Based on this target, we can define a potential field for trajectory following as

with  a small value. Our velocity commands are then obtained from the vector field
a small value. Our velocity commands are then obtained from the vector field

with  a positive constant.
a positive constant.
Results
We first demonstrate the speed and effectiveness of our approach quantitatively by comparing against a traditional planning algorithm (RRT*) and a state-of-the-art reactive control scheme [7]. For our quantitative comparisons in static environments (Table 1), we use Isaac Gym and evaluate performance in 5 different cluttered scenes with 100 random start and goal pair configurations. For dynamic environments (Table 2), we set up the same cluttered environments in simulation and add a single moving obstacle traversing the scene with constant velocity. Our experiments in static environments indicate that RAMP can generate paths with high success rates that are comparable to traditional and state-of-the-art approaches in terms of total trajectory length, while being up to 30 times faster. On the other hand, in dynamic environments, RAMP achieves the highest number of collision-free iterations and tends to maintain a higher safety distance to obstacles on average. This verifies that our method achieves safer motion in dynamic environments compared to alternatives.

Table 1. Static environment comparison

Table 2. Reactivity comparison with a moving obstacle
Additionally, we integrate our planning algorithm within a complete pipeline for table clearing and qualitatively demonstrate its capabilities, both in static environments with many objects and in scenes with moving obstacles. Similarly to our numerical experiments, we run our motion planning algorithm with the whole dishwasher loading pipeline in 5 static and 5 dynamic environments. For each scene, we randomly generate tabletop scenarios with a maximum number of 5 objects to be loaded to the dishwasher tray. In static scenes, we place a box-shaped obstacle among the tabletop objects to make the problem more difficult (see Figure. 3) whereas in dynamic scenes, a human operator randomly moves the same box-shaped obstacle to perturb the execution of the task (see Figure. 4).
The robot managed to successfully place 19/21 objects totally in the static environments, with one grasping failure and one collision. Of those 19 objects, 7 also required leftover disposal before placing. The grasping failure was not directly related to our motion planning algorithm, since it was associated with a lack of a feasible inverse kinematics solution when grasping one of the plates, whereas the collision was related to the asymmetric shape of link 5 of the Panda robot, which cannot be entirely captured by control points on the body skeleton. We believe that sampling control points directly from the meshes of the robot links can resolve this issue, but might make the algorithm slightly slower.

Figure 3. Real-world experiment in a static environment. We demonstrate the performance of RAMP in various static environments with bowls, plates, and utensils. The robot successfully performs table clearing tasks requiring collision-free navigation to specific end effector poses or joint configurations.
In the dynamic scene scenarios, the robot managed to place all 18 objects in total. Of those 18 objects, 8 required leftover disposal before placing. We recorded two minor collisions with the obstacle box: one in which we moved the box too fast toward the robot (which we consider an adversarial case), and one in which the box was briefly behind the robot body and was not visible by the external camera observing the scene. Our results and success rates demonstrate the effectiveness and reliability of our reactive motion planning architecture, in complex real-world scenarios with non-trivial placement tasks.

Figure 4. Real-world experiment with a moving obstacle. The robot approaches target objects while avoiding the moving obstacle or keeping a safe distance from it.
Conclusions
This work presented a reactive motion planning architecture (RAMP) which integrates a fast MPPI-based trajectory generator and an online vector field-based trajectory follower. To ensure safety while trajectory following in dynamic environments with obstacles, RAMP uses Signed Distance Function (SDF) representations, both for fast collision checking and real-time reactive control. Our method can generate collision-free and smooth trajectories and execute them while reacting to dynamic obstacles. Experiments indicate that RAMP is significantly faster than the baselines and ensures safety by minimizing collisions, even with moving obstacles. In table clearing scenarios, RAMP successfully picked up, disposed leftovers from and placed 37 out of 39 objects. In our future work, we would like to incorporate multi-modal sensors (e.g., tactile or acoustic sensors) for feedback, and further investigate online implicit scene representations.
Link to the paper
Vasileios Vasilopoulos, Suveer Garg, Pedro Piacenza, Jinwook Huh, Volkan Isler, “RAMP: Hierarchical Reactive Motion Planning for Manipulation Tasks Using Implicit Signed Distance Functions”, IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 2023.
arXiv: https://arxiv.org/abs/2305.10534
Project Website: https://samsunglabs.github.io/RAMP-project-page/
Code: https://github.com/SamsungLabs/RAMP
References
[1] O. Khatib, “Real-time obstacle avoidance for manipulators and mobile robots”, The International Journal of Robotics Research, vol. 5, no. 1, pp. 90-98, 1986.
[2] E. Rimon and D. E. Koditschek, “Exact robot navigation using artificial potential functions”, IEEE Transactions on Robotics and Automation, vol. 8, no. 5, pp. 501-518, 1992.
[3] S. M. LaValle, Planning Algorithms. Cambridge University Press, 2006.
[4] G. Williams, P. Drews, B. Goldfain, J. M. Rehg, and E. A. Theodorou, “Information-theoretic model predictive control: Theory and applications to autonomous driving”, IEEE Transactions on Robotics, vol. 34, no. 6, pp. 1603-1622, 2018.
[5] G. Sutanto, A. Wang, Y. Lin, M. Mukadam, G. Sukhatme, A. Rai, and F. Meier, “Encoding physical constraints in differentiable Newton-Euler algorithm”, ser. Machine Learning Research, 2020, pp. 804-813.
[6] O. Arslan and D. E. Koditschek, “Smooth extensions of feedback motion planners via reference governors”, in IEEE International Conference on Robotics and Automation, 2017, pp. 4414-4421.
[7] M. Danielczuk, A. Mousavian, C. Eppner, and D. Fox, “Object rearrangement using learned implicit collision functions”, in IEEE International Conference on Robotics and Automation, 2021, pp. 6010-6017.