Robotics
ASGrasp: Generalizable Transparent Object Reconstruction and 6-DoF Grasp Detection from RGB-D Active Stereo Camera
1 Introduction
Recent years have witnessed enormous progress in the field of learning-based diffuse object grasping from depth observations. However, commercial depth sensors fail to accurately sense transparent and specular objects, therefore grasping these kind of objects has become a major bottleneck in developing full 3D sensor solution to general grasping tasks.

Figure 1. Overview of proposed method ASGrasp and the dataset
In this work, we propose to leverage the raw IR observations from an active stereo camera that are commonly found in commercial products(e.g., Intel R200 and D400 family) to improve transparent object depth estimation and grasping detection. Our insight is that the left and right IR observations, before going through error prone stereo matching, carry the original information of transparent object depth while RGB information can provide extra shape priors. We thus devise an RGB aware learning-based stereo matching network that take inputs both RGB and two IR images, based upon a popular flow estimation network.
2 Method
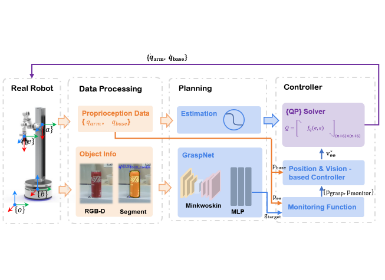
Our proposed framework consists of two main components: the scene reconstruction module, denoted as F_d, and the grasp detection module based on explicit point cloud, denoted as F_g, as illustrated in the Fig.2. In F_d, we choose the RGB image I_c as the reference image and differentiably warp the left I_ir^l and right IR images I_ir^r to the RGB reference coordinate system, constructing a cost volume C∈R^(H×W×D_h ). This allows us to leverage the classical GRU-based stereo matching method. Additionally, we introduce a second-layer depth branch that enables the network to predict not only the visible depth, refer to it as the first-layer depth D_1∈R^(H×W) but also attempts to recover second-layer depth D_2 for objects in the scene, which help to capture the complete 3D shape of unoccluded obejcts. In F_g, we employ the two-stage grasping network F_gsnet, and thanks to the richer input point cloud information, the F_gsnet can predict more accurate grasp poses in the second stage.

Figure 2. Architecture of our system
2.1 Scene Reconstruction
For single-view grasping networks, one crucial aspect is the accurate recovery of scene depth, especially for transparent and specular objects. Additionally, the single-view depth only record the first intersection point of rays with the surfaces of objects in the scene. With only partial object shape information available, predicting optimal grasp poses becomes a more challenging task for the grasping network, particularly when dealing with lateral grasping orientations. To address this challenge, we propose a framework based on RAFT-like stereo matching that simultaneously recovers first layer depth for transparent and specular objects as well as occluded surface information for objects by second-layer depth prediction.
2.2 Point Cloud Based Grasp Detection
Our point cloud based grasp detection network is built upon the SOTA work, GSNet[1]. The original GSNet is a two-stage grasp detector to predict dense grasp poses from a single-view point cloud. To extract comprehensive geometric features of the scene, our network F_g takes not only visible but also invisible point clouds as inputs, which are obtained by sampling from the first and second-layer depths, respectively. The visible point cloud serves as the primary resource for generating augmented grasp points for the subsequent neural network, while the invisible point cloud is used as a reference to provide additional contextual features.
2.3 Synthetic Dataset Generation
Existing grasping datasets like [1] don’t include transparent and specular objects, while current datasets for these materials lack dense grasping annotations. We introduce a synthetic grasping dataset featuring transparent and specular objects which comprises 115k sets of RGB and IR images, along with 1 billion grasp poses. We create this dataset using a data generation pipeline based on [2]. Initially, we modify the object materials in [1] to include diffuse, specular, or transparent properties, so we name it STD-GraspNet. Subsequently, we use Blender to generate photorealistic RGB and IR images, utilizing the settings of the Realsense D415 camera. To address the challenge of sim-to-real gap, we apply domain randomization in [2]. In terms of camera poses, we not only use the original poses from [1], but also add 3k additional random camera poses to enhance diversity and mimic various distances to objects. We train our networks with STD-GraspNet, treating real data as a training data variation, thus improving realworld performance.
3 Results
3.1 Scene Reconstruction Experiment
We first compare our first-layer depth with state-of-the-art methods on the test split of DREDS-CatKnown [2], including LIDF, NLSPN and SwinDR. All baselines are trained on the training split of DREDS-CatKnown. Subsequently, we compare our results with SwinDR on STD-GraspNet test split after fine-tuning on STD-GraspNet training split. As shown in Table I and Table II, we achieve the best performance compared to other methods on DREDS and STDGraspNet for the first-layer depth. Due to the absence of a suitable baseline, we can only report our performance for the second-layer depth. The simulated raw point cloud contains missing and wrong points. We observe that SwinDR restores missing parts well, but performs poorly in areas with incorrect data. Our method performs much better in both the first and second layers, yielding a high-quality complete point cloud reconstruction.

Table I. Depth completion quantitative comparison on DREDS-CatKnown dataset

Table II. Evaluation of reconstruction on STD-GraspNet test split

Figure 3. Qualitative comparison of point cloud reconstruction for an exemplar test data
3.2 Simulation Grasping Experiments
Table III shows our simulation grasping result for different point cloud inputs with GSNet trained with corresponding data. GSNet(RealRaw) with simulated raw depth map which contain incorrect depth or missing on transparent objects, leading the low performance. Although SwinDR improves the depth to some extent, it still suffers from over-smoothing, resulting in a degradation of grasping performance. For GSNet(SynVisible), input with our predicted visible point cloud achieves similar performance with Oracle(SynVisible), thanks to the original RGB and IR images, learning based stereo matching method and diverse dataset. But we also observe that certain metrics even outperformed the Oracle(SynVisible), which could be caused by the bleeding artifacts near object boundaries, resulting the grasping network to favor grasping pose from the front of objects. For GSNet(SynComplete), utilizing our two-layer complete point cloud has the best performance overall. We observe that it outperformed the Oracle(SynVisible). This further shows the potential for improved grasping accuracy with a complete scene representation. However, there is still a noticeable gap compared to the Oracle(SynComplete).

Table III. Grasp success rate(%) of cluster removal in simulation
3.3 Real Robot Experiments
To evaluate the performance of our method in real world, we conduct grasping experiments as well. Table V shows our realworld grasping evaluation results on the robot, where our method with complete point cloud achieves the highest success rate and declutter rate all test scenes. Compared with original GSNet, our ASGrasp significantly increases the success rate and declutter rate by 55.8% and 67.5% in average. In addition, both visible point cloud and complete point cloud as input can achieve 100% declutter rate.

Table V. Grasp success rate(%)/declutter rate(%) of clutter removal in the real world
4 Conclusion
In this work, we propose an active stereo camera based 6-DoF grasping method, ASGrasp, for transparent and specular objects. We present a two-layer learning based stereo network which reconstructs visible and invisible parts of 3D objects. The following grasping network can leverage rich geometry information to avoid confused grasping. We also propose a large-scale synthetic data to bridge sim-to-real gap. Our method outperforms competing methods on depth metric and clutter removal experiments in both simulator and real world.
References
[1] H.-S. Fang, C. Wang, M. Gou, and C. Lu, “Graspnet-1billion:A large-scale benchmark for general object grasping,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11444–11453, 2020.
[2] Q. Dai, J. Zhang, Q. Li, T. Wu, H. Dong, Z. Liu, P. Tan, and H. Wang, “Domain randomization-enhanced depth simulation and restoration for perceiving and grasping specular and transparent objects,” in European Conference on Computer Vision, pp. 374–391, Springer, 2022.