Security & Privacy
Social Listening for Threat Intelligence
“Part 1: Keep your friends close and your enemies closer.”
“Keep Your Enemies Closer”
It’s noteworthy that both Sun Tzu, a famous military strategist in the East, and Al Pacino’s Michael Corleone, the main character of the Western film “The Godfather,” adhere to the same strategy: “Keep your friends close and your enemies closer.” This tells us the importance and relevance of being vigilant against enemy threats. Today, this philosophy is especially relevant in the field of cybersecurity. The more we rely on connected devices, the more we are exposed to attackers. As attacks become more sophisticated and diverse, we will more likely lose the game if we don’t pay attention to our attackers’ actions.
Because preventive measures are better than reactive measures, we aim to eliminate potential vulnerabilities as many as possible throughout the software development process. To this end, we take on the security development lifecycle (SDL) approach—from requirements to design and from implementation to testing. Automated tools and manual penetration testing also help identify vulnerabilities before the release of our products.
However, complete prevention against cyber threats cannot be guaranteed because of the complexity of the modern software running on connected devices. Thus, it is crucial to keep monitoring the security risks relevant to our products. We could mitigate the risk of cyber threats by capturing their ongoing symptoms as early as possible. These detected threats enable us to analyze their potential impact and quickly respond appropriately.
Where should we sense threats?
Information related to security threats, vulnerabilities, and attacks is published daily on various informal sources such as social media platforms, blogs, and developer fora. Moreover, it is almost impossible for human analysts to manually review and evaluate an attack’s relevance to our products. For this reason, we are looking to adopt an automated detection technology against cyber threats.
First, we investigated which data sources are suitable for early-stage security monitoring. We explored the timelines of mentions of about 105 notable cybersecurity incidents over various data sources, from mainstream news to developer fora.
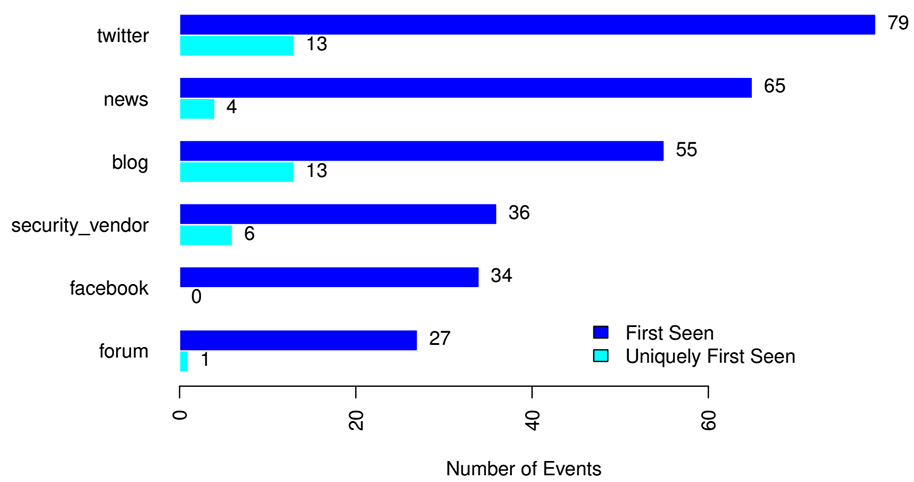
No. of Events
Figure 1: The distribution of data source types on the first day of 105 events. The value after each bar indicates the no. of events.
Figure 1 shows that 75% of the events were discussed on Twitter on the same day as other source types or earlier. We believe that this is because people use Twitter as an information propagation platform. News outlets, security firms, and individual security researchers often use Twitter to quickly disseminate their findings of malware and vulnerabilities after publishing their original articles or reports via their websites. More results are included in our paper that supports the claim that Twitter is a useful source for detecting cyber threats. In conclusion, Twitter is the main source and, sometimes, the only source to spread information on cybersecurity events.
What is our challenge?
Having proved that Twitter is an appropriate data source, capturing threats early and accurately remains a challenge. We observed that most cybersecurity events are only discussed by a few users in their early stages and remain unknown for a while until their impacts are analyzed. Mentions of such events only peak after a few days. Thus, event detection algorithms requiring a large volume of mentions cannot detect threats in their early stages, as seen in Figure 2. On the other hand, simple key word–based detection approaches can detect threats early, but they incur a large number of false detections.

Figure 2: Two challenges to consider when detecting cyber threats via Twitter.
What is our main idea for the challenge?
We designed a cybersecurity event detector based on our two major observations.
First, we observed that the names of malware and vulnerabilities, such as WannaCry, Petya, NotPetya, Cerber, GandCrab, Shellshock, Heartbleed, Badlock, and KRACK, are not often stated as common English terms. This observation brought us to the conclusion that if we could identify new words from tweets regarding cybersecurity, we can detect security events on their first appearance.
Second, we observed that there are many security events that feature no novel words at all. For example, we could not find any new words in tweets when someone mentioned “Spectre,” a vulnerability in Intel CPUs. Thus, instead of searching for the word itself, we needed to focus on other changes. When Spectre became public, we observed that the frequency of the word “Intel” was unusually higher than the other days. Therefore, by monitoring the sudden frequency change of the words that are targets of the attack, we could capture security events that use common English words.
Figure 3 illustrates the second idea. It shows the number of mentions of “Intel” and “Spectre” from Dec. 2017 to Jan. 2018. The grey and blue dotted lines represent the upper bounds for frequencies of “Intel” and “Spectre,” respectively. The yellow and cyan spotted circles represent the days that the words are flagged as re-emerging terms. Both “Intel” and “Spectre” identified the “Spectre” vulnerability on its first day (Jan. 3, 2018).

Figure 3. The number of mentions of “Intel” and “Spectre.”
We named our word-based event detector “W2E: Words to Events.” Figure 4 illustrates the workflow of W2E. We provided all the details in the published paper titled “Cybersecurity Event Detection with New and Re-emerging Words.”

Figure 4: The workflow of our cybersecurity event detection system.
Is it beneficial?
Definitely! We have been running W2E to detect cyber threats and respond as quickly as possible. So far, we’ve detected and proactively responded to hundreds of cyber threats that might impact our products. On https://samsunglabs.github.io/W2E/, you can see some of the daily detected events.
We hope this is good news to all our consumers and bad news to those who plan to attack us.
Link to the paper
https://dl.acm.org/doi/10.1145/3320269.3384721?cid=81460651861




