AI
MetaCC: A Channel Coding Benchmark for Meta-Learning
TL;DR: We propose channel coding as a novel benchmark to study several aspects of meta-learning, including the impact of task distribution breadth and shift on meta-learner performance, which can be controlled in the coding problem.
Introduction
Challenges in Studying of Meta-Learning
Meta-learning, or learning-to-learn, has recently grown into a thriving research area in which rapid progress is being made [1, 2, 3], thanks to its proven ability to learn new tasks in a data-efficient manner. While performance has improved steadily, particularly on standard image recognition benchmarks, several fundamental outstanding challenges have been identified [3]. Notably, state-of-the-art meta-learners have been shown to suffer in realistic settings [4, 5], when the task distribution is broad and multi-modal; and when there is distribution shift between the (meta)training and (meta)testing tasks. These conditions are relevant in most real-world applications. For example, robots should generalize across the range of manipulation tasks of interest to humans [4], and image recognition systems should cover a realistically wide range of image types [5].

Figure 1. Schematic illustration of meta-learning scenarios. Top: The typical assumption of training distribution being equal to testing distribution  is rarely met in practice. Bottom: Realistic scenarios pose distribution shift between training
is rarely met in practice. Bottom: Realistic scenarios pose distribution shift between training  and deployment
and deployment  .
.
However, systematic study of these issues is hampered because conventional benchmarks do not provide a way to quantitatively measure or control the complexity or similarity of task distributions: Does an image recognition benchmark covering birds and air-planes provide a more or less complex task distribution to meta-learn than one covering flowers and vehicles? Is there greater task-shift if a robot trained to pick up objects must adapt to opening a drawer or throwing a ball?
In a recent paper [6], we contribute to the future study of these issues by introducing a channel coding meta-learning benchmark termed MetaCC, which enables finer control and measurement of task-distribution complexity and shift.
Channel Coding Relevance
Channel coding is a classic problem in communications theory. It is about how to encode/decode data to be transmitted over a capacity limited noisy channel so as to maximize the fidelity of the received transmission. While there is extensive theory on optimal codes for analytically tractable (e.g., Gaussian) channels, recent work has shown that codecs obtained by deep learning provide clearly superior performance on more complex challenging channels [7].
Existing best neural channel coding is achieved by training codecs tuned to the noise properties of a given channel. Thus, a highly practical meta-learning problem arises: Meta-learning a channel code learner on a distribution of training channels, which can rapidly adapt to the characteristics of a newly encountered channel. For example, the role of meta-learning is now to enable the codec of a user's wireless mobile device to rapidly adapt for best reception as she traverses different environments or switches on/off other sources of interference.
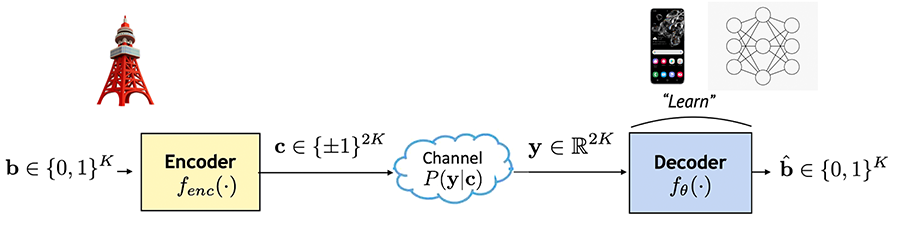
Figure 2. An illustration of the channel coding problem.
We introduce channel coding problems as tasks to study the performance of meta-learners, defining the MetaCC benchmark to complement existing ones [4, 5]. Our benchmark spans five channel families, including a real-world measurement of channels based on Software Defined Radio (SDR). We show how the channel coding problem uniquely leads to natural model-agnostic ways to measure the breadth of a task distribution, as well as the shift between two task distributions (Fig. 1) – quantities that are not straightforward to measure in vision benchmarks.
Building on these metrics, we use MetaCC to answer the following questions, among others:
Q1: How vulnerable are existing meta-learners to under-fitting when trained on complex task distributions?
Q2: How robust are existing meta-learners to task-distribution shift between meta-train and meta-test task distributions?
Q3: How much can meta-learning benefit in terms of transmission error-rate on a real radio channel?
Background
Channel Coding
A typical channel coding system consists of an encoder and a decoder, as illustrated in Fig. 2. In this example a rate 1/2 channel encoder maps K message bits 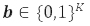 to a length-2K transmitted signal
to a length-2K transmitted signal  . In a more general setting a rate 1⁄r encoder maps
. In a more general setting a rate 1⁄r encoder maps 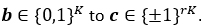 The signal c is then transmitted with the noise effect experienced by the signal in the communication medium described by conditional distribution
The signal c is then transmitted with the noise effect experienced by the signal in the communication medium described by conditional distribution  , and channel outputs a noisy signal
, and channel outputs a noisy signal  A canonical example is Additive White Gaussian Noise (AWGN) channels, where
A canonical example is Additive White Gaussian Noise (AWGN) channels, where  for Gaussian
for Gaussian  The decoder in turn takes the noisy signal as input and estimates the original message, i.e.
The decoder in turn takes the noisy signal as input and estimates the original message, i.e.  The reliability of an encoder/decoder pair is measured by the probability of error, such as Bit Error Rate (BER) defined as
The reliability of an encoder/decoder pair is measured by the probability of error, such as Bit Error Rate (BER) defined as 
We treat the decoding problem as a K-dimensional binary classification task for each of the ground-truth message bits bk.
Adaptive Neural Decoder
The channel can vary over time, and is unknown to the decoder. To help the decoder estimate the channel, pilot signals that are known messages bknown are sent to the decoder before the transmission begins, so that the decoder can extract channel information from y and bknown.
When modeling the decoder as a neural network instead of an analytical algorithm, one trains the decoder for a specific channel using pairs (y,bknown) with pilot signals as ground-truths and their corresponding noisy received values as inputs. The optimization goal is to minimize a loss  , which is typically in form of binary cross-entropy, with respect to decoder
, which is typically in form of binary cross-entropy, with respect to decoder 
To ensure good performance as channel characteristics change due to e.g. weather or moving users, which always happen in realistic communications, the neural decoder fθ should adapt to evolving channel. Meta-learning is therefore a promising tool to enable rapid decoder adaptation with few pilot codes, as confirmed by early evidence [8]. Conversely, channel coding provides a lightweight benchmark for contemporary meta-learners, allowing control of the task complexity and distribution-shift, thanks to the mathematical representability and tractability of channel models.
Benchmarking Meta-Learning
We consider five families of channel models including both synthetic channels (AWGN, Bursty, Memory noise, and Multipath interference channel) and real-world channel with data recorded from a software-defined radio testbed. Each family is analogous to a dataset in common multi-dataset vision benchmarks [5].
To define task distributions, we consider uni-modal and multi-modal settings. In the single-family, uni-modal case, a task distribution p corresponds to a specific channel class as discussed above, parameterized by continuous channel parameters ω (e.g., the variance of additive noise or multipath strength). The distribution of tasks in this family then depends on the prior over channel parameter  We can control the width of a task distribution by varying the width of the, e.g. uniform distributed, prior p(ω). In the multi-family, multi-modal case we can define a more complex task distribution as a mixture over multiple channel types pk, each with its own distribution over channel parameters
We can control the width of a task distribution by varying the width of the, e.g. uniform distributed, prior p(ω). In the multi-family, multi-modal case we can define a more complex task distribution as a mixture over multiple channel types pk, each with its own distribution over channel parameters 
We quantify the train-test task shift distance (Definition 1) and diversity of each task (Definition 2), based on information theoretic measures. In the proposed coding benchmark, as we demonstrate this in the full paper, one can control these scores by choosing an appropriate set of channel models, which allows us to evaluate the variability of meta-learning with the task distribution breadth and shift as illustrated in Fig. 1.
Definition 1: Train-Test Task-Shift measures have previously been an open problem in meta-learning. However, this becomes feasible to define for the channel coding problem. We quantify the distance between a test distribution pa (T) and a training distribution pb(T) using the Kullback–Leibler divergence (KLD) a.k.a. the relative entropy. Given pa (ya|c)and pb (yb |c) denote the channels associated with Ta and Tb respectively. The KLD-based shift distance score is defined as:

Definition 2: Diversity Score of a task distribution p(T) is defined as mutual information between the channel parameter ω and the received signal y:

Where ω denotes the channel parameter a.k.a latent variable for the task distribution, i.e.,  We will see that this metric will quantify amenability to meta-learning. Intuitively, decoding can benefit more from meta-learning when the channel distribution p(y|c,ω) differs more across tasks (channel parameterω). I.e., knowing the task conveys more information abouty.
We will see that this metric will quantify amenability to meta-learning. Intuitively, decoding can benefit more from meta-learning when the channel distribution p(y|c,ω) differs more across tasks (channel parameterω). I.e., knowing the task conveys more information abouty.

Figure 3. Left: Bit Error Rate (BER) of benchmarked learners at test time under within-family Focused or Expanded training distribution. ‘Mixed’ column: cross-family setting with a mixture of all task families. Right: Testing on an example channel family, i.e. Memory, of models trained on 4 different source channels. Box indicates when meta-training and meta-testing task families align.
Evaluation
The full paper covers the description of extensive evaluation we carried out, which covers 10+ meta-learning algorithms including both gradient-based and prototypical feed-forward meta-learners, under a range of channel distribution complexity & train-test shift scenarios. Here we focus on the results highlighting the answers to Q(1-3) introduced above.
Q1 & Q2: Fig.3 shows that the absolute accuracy degrades with both training distribution diversity in (left) and train-test distribution shift (right) on meta-learning performance.
Q2 & Q3: Fig.4 indicates the performance margin of adaptive neural decoders based on meta-learning tends to improve with distribution-shift (left), and meta-learning can achieve up to 58% and 30% reduction in error rate compared to the Empirical Risk Minimisation (ERM) and classic Viterbi respectively (right).

Figure 4. Left: Performance margin of adaptive neural decoders based on meta-learning tends to improve with distribution-shift. Right: Meta-learner achieves up to 58% and 30% reduction in error rate compared to the ERM and Viterbi respectively.
Why To Use MetaCC Benchmark
▷ It provides a systematic framework to evaluate future meta-learner performance w.r.t under-fitting complex task distributions and robustness to train-test task distribution shift that is ubiquitous in real use cases such as sim-to-real
▷ MetaCC is independently elastic in every dimension e.g., number of tasks, instances or categories; dimension of inputs; difficulty of tasks, width of task distributions and train-test distribution shift; making it suitable for the full spectrum of research from fast prototyping to investigating the peak scalability of meta-learners
▷ MetaCC provides an opportunity to study robustness to domain-shift by enabling direct comparisons to ERM and Viterbi
▷ Real-world significance in communication systems and sim-to-real transition
Take Home Message
We present a channel coding based benchmark for meta-learning that is elastic in terms of number of tasks, categories, difficulty of tasks, width of task distributions and train-test distribution shift. We use this to demonstrate the ability to improve neural channel decoding by fast adaptation, and to provide a tool for the study of meta-learning through fast prototyping and ability to investigate scalability, generalization and meta over/under-fitting.
Acknowledgement
Credits to my co-authors: Ondrej Bohdal, Rajesh Mishra, Hyeji Kim, Da Li, Nicholas Lane, and Timothy Hospedales
Link to the paper
Reference
[1] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In ICML, 2017.
[2] Luisa M Zintgraf, Kyriacos Shiarlis, Vitaly Kurin, Katja Hofmann, and Shimon Whiteson. Fast context adaptation via meta-learning. In ICML, 2019.
[3] Timothy M Hospedales, Antreas Antoniou, Paul Micaelli, and Amos J. Storkey. Meta-learning in neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2021.
[4] Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In CORL, 2019.
[5] Eleni Triantafillou, Tyler Zhu, Vincent Dumoulin, Pascal Lamblin, Utku Evci, Kelvin Xu, Ross Goroshin, Carles Gelada, Kevin Swersky, Pierre-Antoine Manzagol, and Hugo Larochelle. Meta-dataset: A dataset of datasets for learning to learn from few examples. In ICLR, 2020.
[6] Rui Li, Ondrej Bohdal, Rajesh Mishra, Hyeji Kim, Da Li, Nicholas Lane, and Timothy Hospedales. "A Channel Coding Benchmark for Meta-Learning." In NeurIPS 2021 Benchmark and Dataset Track .
[7] Hyeji Kim, Yihan Jiang, Ranvir Rana, Sreeram Kannan, Sewoong Oh, and Pramod Viswanath. Communication algorithms via deep learning. In ICLR, 2018.
[8] Yihan Jiang, Hyeji Kim, Himanshu Asnani, and Sreeram Kannan. Mind: Model independent neural decoder. In 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), 2019.