AI
[CVPR 2022 Series #4] Stereo Magnification with Multi-Layer Images
|
The Computer Vision and Pattern Recognition Conference (CVPR) is a world-renowned international Artificial Intelligence (AI) conference co-hosted by the Institute of Electrical and Electronics Engineers (IEEE) and the Computer Vision Foundation (CVF) which has been running since 1983. CVPR is widely considered to be one of the three most significant international conferences in the field of computer vision, alongside the International Conference on Computer Vision (ICCV) and the European Conference on Computer Vision (ECCV). This year Samsung Research’s R&D centers around the world present a total of 20 thesis papers at the CVPR 2022. In this relay series, we are introducing a summary of the 6 research papers. Here is a summary of the 6 research papers among 20 thesis papers shared at CVPR 2022. - Part 1 : Probabilistic Procedure Planning in Instructional Videos (by Samsung AI Center – Toronto) - Part 3 : GP2: A Training Scheme for 3D Geometry-Preserving and General-Purpose Depth Estimation - Part 4 : Stereo Magnification with Multi-Layer Images (by Samsung AI Center - Moscow) - Part 5 : P>M>F: The Pre-Training, Meta-Training and Fine-Tuning Pipeline for Few-Shot Learning - Part 6 : Gaussian Process Modeling of Approximate Inference Errors for Variational Autoencoders (by Samsung AI Center - Cambridge) |
About Samsung AI Center – Moscow
The Samsung AI Research Center in Moscow, SAIC-Moscow, is dedicated to the creating of the world's first solutions that push the boundaries of AI with a major focus on the multimedia processing and scene understanding.
One of the research topics at SAIC-Moscow is Spatial AI, which implies the development of visual-based and multimodal-based systems capable of analyzing the real environment. The solutions created by the Spatial AI team might be employed to improve navigation and manipulating objects in robotics, facilitate scene modeling in AR applications, or generate prompts in personal assistant applications.
Another core research topic at SAIC-Moscow is multimedia processing, which includes generating and manipulating visual and audial data. We have already authored numerous publications on image synthesis and speech enhancement. Below, we revise their most recent work, accepted to CVPR, that focuses on the 3D photo synthesis. Existing 3D photo synthesis approaches necessitate high-capacity memory and processing capabilities, which severely restricts their applicability. The proposed method demonstrates competitive performance while being extremely memory-efficient, thereby opening new opportunities for the fast and efficient 3D photo synthesis on mobile devices.
Introduction
Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape.
In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer, and are trained in an end-to-end manner.


View extrapolations obtained by our method. The two input images are shown in the middle. The proposed method (StereoLayers) generate plausible renderings even when the baseline is magnified by a factor of 5x (as in this case). Image taken from LLFF dataset [2].
Method and Motivation
It was shown previously that with two or more input images, one can represent a scene as a regularly spaced set of fronto-parallel rigid planes. Each plane is equipped with a texture consisting of RGB color and opacity channel. Such a representation is called a multi-plane image or MPI. A notable advantage of this proxy geometry is real-time rendering. Prior works have proved that it is possible to train a convolutional network on a dataset of scenes to predict MPI geometry for an arbitrary scene with a limited field of view. Even though MPI estimation is feasible, the number of rigid planes required to plausibly approximate the scene, is relatively large: prior methods usually used 32 to 128 planes. The main reason is the difficulty of reproducing curved objects using planar geometry (see Fig. 2 left column). There are existing methods [4, 5] that propose an heuristics to merge planes into layers and represent the scene as a stack of semi-transparent mesh layers, where the number of layers is significantly less than the number of planes. Unfortunately, this procedure can introduce additional discontinuities during merging (see Fig.2) if the heuristic does not work optimally.

Figure 1. The proposed StereoLayers pipeline estimates scene-adjusted multi-layer geometry from the plane sweep volume using a pretrained geometry network, and after that estimates the color and transparency values using a pretrained coloring network. The layered geometry represents the scene as an ordered set of mesh layers. The geometry and the coloring networks are trained together end-to-end. Image source
In contrast, our method presented in figure 1 initially estimates the proxy geometry as several non-rigid layers. Afterward, the color and opacity channels for the predicted layers are recovered.
Both steps are implemented with deep convolutional networks. These networks are trained together with photometric supervision in an end-to-end manner on a dataset of videos. The obvious benefit of our method is that we produce an adaptive multi-layer representation for any scene. This allows for using just 4 layers for a scene. It is important to note, the quality of novel views is no worse than with a set of rigid planes. Modern computer graphics engines such as OpenGL still allow rendering of the proposed representation in real time.
However, our method still has some weak points inherited from the baseline method. Among them, the input stereo-pair is processed asymmetrically, and the cost of extending our approach for more than two given views is high. Despite this, our model produces strong results in a stereo magnification task, according to the formal metrics and human preference study.


Reference, Ours (2 soft layers), Ours (2 GC layers), Ours (4 soft layers), Broxton et al. 4 layers, Zhou et al. (32 planes)
Figure 2. Geometry estimated for different configurations. For the two stereo pairs (only reference views are shown), we visualize horizontal slices along the blue line. Mesh vertices are shown as dots with the predicted opacity. Colors encode the layer number. The horizontal axis corresponds to the pixel coordinate, while the vertical axis stands for the vertex depth w.r.t. the reference camera (only the most illustrative depth range is shown). StereoLayers method variants generate scene-adaptive geometry in a more efficient way than StereoMag [1] resulting in more frugal geometry representation, while also obtaining better rendering quality. Images are taken from LLFF dataset.
Results
In this section we describe the results of method with best setup of depth and texture aggregation. Please refer to the main publication to see additional details.
Alongside the new method, we also propose a new dataset of videos called SWORD (the Scenes With Occluded Regions Dataset) for training models of novel view synthesis. Compared to the popular RealEstate ten K dataset, our dataset contains more large central objects with more occluded parts.

Table 1. Results of the evaluation on LLFF datasets [2], models were trained on SWORD. All metrics are computed on central crops of synthesized novel views. Our approach outperforms all baselines on these datasets, although it contains fewer layers in the scene proxy. In particular, the StereoLayers method surpasses IBRNet despite the fact that the latter was trained on 80% of LLFF scenes in a multiview setting. The digit after the type of the model denotes the number of layers in the estimated geometry. Broxton et al. model stands for the postprocessing over the MPI.
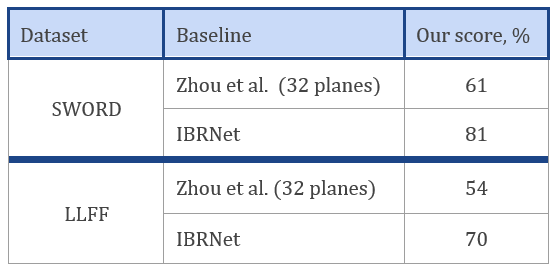
Table 2. User study Results : The score is the ratio of users who selected the output of our model (StereoLayers-4) as more realistic in side-by-side comparison.
Conclusion
In this work, we proposed an end-to-end pipeline that recovers the geometry of the scene from an input stereo pair using a fixed number of semitransparent layers. Despite using fewer layers (4 layers vs. 32 planes for the baseline StereoMag model), our approach demonstrated superior quality in terms of commonly used metrics for the novel view synthesis problem, as well as human evaluation. Unlike the StereoMag system, the quality of which heavily depends on the number of planes, our method has reached better scores while being robust to reducing the number of layers. We have verified that the proposed method can be trained on multiple datasets and generalizes well to unseen data. The resulting mesh geometry can be effectively rendered using standard graphics engines, making the approach attractive for mobile 3D photography. Additionally, we presented a new challenging SWORD dataset, which contains cluttered scenes with heavily occluded regions. Even though SWORD consists of fewer scenes than the popular RealEstate10K dataset, systems trained on SWORD are likely to generalize better to other datasets, e.g. the LLFF dataset.
Related Page
- Project Page : https://samsunglabs.github.io/StereoLayers/
Link to the paper
References
[1] Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images. In Proc. ACM SIGGRAPH 2018
[2] Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines, Ben Mildenhall, Pratul Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, Abhishek Kar, s. In Proc. ACM SIGGRAPH 2019
[3] Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erickson, Peter Hedman, Matthew Duvall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. Immersive light field video with a layered mesh representation. In Proc. ACM SIGGRAPH, 2020
[4] Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P. Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. In CVPR 2021
[5] Kai-En Lin, Zexiang Xu, Ben Mildenhall, Pratul P. Srinivasan, Yannick Hold-Geoffroy, Stephen DiVerdi, Qi Sun, Kalyan Sunkavalli, and Ravi Ramamoorthi. Deep multi depth panoramas for view synthesis. In Proc. ECCV, 2020.

