AI
[CVPR 2022 Series #3] GP2 : A Training Scheme for 3D Geometry-Preserving and General-Purpose Depth Estimation
|
The Computer Vision and Pattern Recognition Conference (CVPR) is a world-renowned international Artificial Intelligence (AI) conference co-hosted by the Institute of Electrical and Electronics Engineers (IEEE) and the Computer Vision Foundation (CVF) which has been running since 1983. CVPR is widely considered to be one of the three most significant international conferences in the field of computer vision, alongside the International Conference on Computer Vision (ICCV) and the European Conference on Computer Vision (ECCV). This year Samsung Research’s R&D centers around the world present a total of 20 thesis papers at the CVPR 2022. In this relay series, we are introducing a summary of the 6 research papers. Here is a summary of the 6 research papers among 20 thesis papers shared at CVPR 2022. - Part 1 : Probabilistic Procedure Planning in Instructional Videos (by Samsung AI Center – Toronto) - Part 3 : GP2: A Training Scheme for 3D Geometry-Preserving and General-Purpose Depth Estimation - Part 4 : Stereo Magnification with Multi-Layer Images (by Samsung AI Center - Moscow) - Part 5 : P>M>F: The Pre-Training, Meta-Training and Fine-Tuning Pipeline for Few-Shot Learning - Part 6 : Gaussian Process Modeling of Approximate Inference Errors for Variational Autoencoders (by Samsung AI Center - Cambridge) |
About Samsung AI Center – Moscow
The Samsung AI Research Center in Moscow, SAIC-Moscow, is dedicated to the creating of the world's first solutions that push the boundaries of AI with a major focus on the multimedia processing and scene understanding.
One of the research topics at SAIC-Moscow is Spatial AI, which implies the development of visual-based and multimodal-based systems capable of analyzing the real environment. The solutions created by the Spatial AI team might be employed to improve navigation and manipulating objects in robotics, facilitate scene modeling in AR applications, or generate prompts in personal assistant applications.
Many scene understanding applications rely on the 3D scene reconstruction. Accordingly, there is a strong request from the industry for a technology that allows restoring scene geometry from a single image. It is addressed by single-view depth estimation methods that, given an image of a scene, estimate distances to the visible objects. Below, we introduce a novel state-of-the-art single-view depth estimation method presented at CVPR 2022. Unlike its predecessors, the proposed approach does not require resource-intensive post-processing, addressing the task with an efficient, straightforward pipeline.
Background
Nowadays, robotics, AR, and 3D modeling applications attract considerable attention to single-view depth estimation (SVDE) as it allows estimating scene geometry from a single RGB image. Recent works have demonstrated that the accuracy of an SVDE method highly depends on the diversity and volume of the training data. However, RGB-D datasets obtained via depth capturing or 3D reconstruction are typically small, synthetic datasets are not photorealistic enough, and all these datasets lack diversity.
The large-scale and diverse data can be sourced from stereo images or stereo videos from the web. Typically being uncalibrated, stereo data provides disparities up to an unknown shift (geometrically incomplete data), so stereo-trained SVDE methods cannot recover 3D geometry. It was recently shown that the distorted point clouds obtained with a stereo-trained SVDE method can be corrected with additional point cloud modules (PCM) separately trained on the geometrically complete data.
On the contrary, we propose GP2, General-Purpose and Geometry-Preserving training scheme, and show that conventional SVDE models can learn correct shifts themselves without any post-processing, benefiting from using stereo data even in the geometry-preserving setting. Through experiments on different dataset mixtures, we prove that GP2-trained models outperform methods relying on PCM in both accuracy and speed, and report the state-of-the-art results in the general-purpose geometry-preserving SVDE. Moreover, we show that SVDE models can learn to predict geometrically correct depth even when geometrically complete data comprises the minor part of the training set.

Figure 1. Point clouds reconstructed from depth estimates obtained with existing SVDE methods, including our GP2-trained B5-LRN SVDE model. Images are taken from the MS COCO dataset.
Introduction
Early SVDE methods were designed to work either in indoor scenes or in autonomous driving scenarios, thus being domain-specific. Accordingly, these methods demonstrate poor generalization ability in cross-domain experiments [4]. Overall, it is empirically proved that the generalization ability of SVDE models heavily depends on the diversity of the training data [4, 5, 2]. Recently, efforts have been made to obtain depth data from new sources: from computer simulation, via 3D reconstruction [2], or from stereo data. Among them, stereo videos and stereo images collected from the web are the most diverse and accessible data sources. However, the depth data obtained from stereo videos is geometrically incomplete since stereo cameras’ intrinsic and extrinsic parameters are typically unknown. Respectively, disparity from a stereo pair can be computed up to unknown shift and scale coefficients (UTSS). Such depth data can be used as a proxy for a ground truth depth map, but is insufficient to restore 3D geometry. As a result, modern general-purpose SVDE methods trained on stereo data output predictions that cannot be used to recover 3D geometry [4]. Hence, we describe these methods as not geometry-preserving and their predictions as geometrically incorrect.
The only SVDE method that is both general-purpose and geometry-preserving is LeReS [5]. It addresses geometry-preserving depth estimation with a multi-stage pipeline that recovers shift and focal length through predicted depth post-processing. This post-processing is performed using trainable point-cloud modules (PCM), thus resulting in significant overhead. Moreover, training PCM requires geometrically complete data with known camera parameters which limits the possible sources of training data.
In this work, we introduce GP2, an end-to-end training scheme and show that SVDE models can learn correct shift themselves and benefit from training on geometrically incomplete data while being geometry-preserving. To obtain geometrically correct depth predictions, we do not employ additional models like PCM in LeReS [5]. Instead, we use geometrically complete data to encourage an SVDE model to predict geometrically correct depth maps while taking advantage of diverse and large-scale UTSS data. Thus, the proposed training scheme can be applied to make any SVDE model general-purpose and geometry-preserving. To prove this, we train different SVDE models using GP2 and evaluate them on unseen datasets.
Our Method

Figure 2. Overview of the proposed training scheme. We apply a scale-invariant loss on geometrically complete samples and a shift-and-scale invariant loss on all samples. As a result, an SVDE model learns to predict geometrically correct depth, while training on diverse and voluminous geometrically incorrect data ensures generalization.
The key observation behind our scheme is that SVDE models that use UTSS data for training can still learn to make geometrically correct predictions out of UTS samples present in the training mixture. Existing general-purpose methods trained with UTSS data use only UTSS [3, 4, 5] or ranking losses [5], thus missing helpful information about correct depth shifts contained in geometrically complete data. On the contrary, we use this information during training to enforce the geometrical correctness of depth estimates.
Mixing datasets. To train an SVDE model on the mixture of UTS and UTSS data, we propose using a combination of a scale-invariant (UTS) loss and a shift-and-scale-invariant (UTSS) loss; we use the former whereas possible. More formally, we train SVDE models using the following loss function:

where  for UTS samples and 0 for UTSS samples. The UTSS loss forces the SVDE model to generalize to the diverse UTSS stereo datasets, while the UTS loss encourages producing geometrically correct estimates.
for UTS samples and 0 for UTSS samples. The UTSS loss forces the SVDE model to generalize to the diverse UTSS stereo datasets, while the UTS loss encourages producing geometrically correct estimates.
Choosing prediction space. Uncalibrated stereo data provides inverse-depth, or disparity, up to unknown shift and scale; therefore, it cannot be converted into depth straightforwardly. Thus, UTSS SVDE models are typically trained to predict disparities [3, 4]. On the contrary, we aim at training an up-to-scale SVDE model, so we follow best practices for UTS models while choosing prediction space. The advantages of training UTS models to predict depth in logarithmic space are proved empirically, and a number of loss functions for log-depth space are proposed. Eventually, we opt for making log-depth predictions.
Shift-and scale-invariant loss. The existing shift-and scale-invariant loss functions [4, 5] are based on  loss function with additional quantile trimmings or tanh-based adjustments [5]. In this study, we want to mitigate the effects of using elaborate loss functions, so we validate our training scheme in the most straightforward and demonstrative experimental setting. Specifically, we use a pure loss function without any additional terms.
loss function with additional quantile trimmings or tanh-based adjustments [5]. In this study, we want to mitigate the effects of using elaborate loss functions, so we validate our training scheme in the most straightforward and demonstrative experimental setting. Specifically, we use a pure loss function without any additional terms.
Let denote log-depth estimated by the model,
denote log-depth estimated by the model,  – estimated depth, and
– estimated depth, and 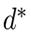 – ground truth depth (for geometrically complete datasets). We can express disparity as
– ground truth depth (for geometrically complete datasets). We can express disparity as  , and ground truth disparity as
, and ground truth disparity as  . Before computing loss function, we align the mean and standard deviation of predictions and ground truth values to make it shift- and scale-invariant:
. Before computing loss function, we align the mean and standard deviation of predictions and ground truth values to make it shift- and scale-invariant:

Then, the UTSS loss function for a single sample can be formulated as:

Scale-invariant UTS loss. Such basic functions as or  , can be used as scale-invariant UTS loss functions. But, a number of more elaborate task-specific scale-invariant loss functions have been introduced: specifically, Multi-Scale Gradient Loss [2], and Pairwise Loss [1]. In our study, we calculate scale-invariant loss function in log-depth space, beforehand we align median of log-differences:
, can be used as scale-invariant UTS loss functions. But, a number of more elaborate task-specific scale-invariant loss functions have been introduced: specifically, Multi-Scale Gradient Loss [2], and Pairwise Loss [1]. In our study, we calculate scale-invariant loss function in log-depth space, beforehand we align median of log-differences:

and UTS loss function can be written as:

Our training scheme does not depend on the choice of a loss function, so other scale-invariant and shift- and scale-invariant losses can be used instead of scale-invariant and shift- and scale-invariant pointwise .
To demonstrate the versatility of our training scheme, we train SVDE models on two datasets mixtures introduced in MiDaS [4] and LeReS [5], respectively. Similar to MiDaS, we train SVDE models on a mixture of four datasets: MegaDepth [2] (denoted as MD for brevity; contains UTS data), DIML Indoor (DIMLI, UTS), RedWeb (RW, UTSS), and Stereo Movies (MV, UTSS). We do not use WSVD dataset from the original mixture. Differently, we use 49 stereo movies (listed in Supplementary) against 23 used in the original MiDaS. The LeReS dataset mixture contains Taskonomy (absolute depths), 3D Ken Burns (absolute), DIML Outdoor (absolute), HoloPix (UTSS), and HRWSI.

Table 1. Results of SVDE models trained on different dataset mixtures with and without GP2. The state-of-the-art results for are marked bold, the second best are underlined. * This model was fine-tuned on the training subset of NYUv2. Other models had never seen any NYUv2 samples during training.
According to average ranks (Table 1), the GP2-trained LeReS SVDE model outperforms the original LeReS+PCM while using the same training data. Moreover, GP2 allows making UTS predictions with a simple single-stage pipeline without any post-processing such as PCM.
A quantitative analysis shows that models trained by the GP2 method achieve better results on unseen during training datasets, both in comparison with previous works, and in comparison with the same architecture trained only on geometrically complete data. On Figure 1, 3 and 4 we compare point cloud reconstructions of depth predicted by our models (referred as B5-LRN) and other previous methods.

Figure 3. Comparison of point clouds obtained with the previous state-of-the-art and our method. Images are taken from the MS COCO dataset.

Figure 4. Point clouds obtained from depth estimates of our B5-LRN model. Paintings are a new data domain unseen during training, however, our method successfully handles these images, estimating depth adequately.
Conclusion
In our work, we presented GP2, a novel scheme of training an arbitrary SVDE model so as it becomes general-purpose and geometry-preserving. Experiments with different SVDE models and multiple dataset mixtures proved that our training scheme improves both depth estimates and point cloud reconstructions obtained with these models. Furthermore, with an SVDE model trained with GP2, we set a new state-of-the-art in the general-purpose geometry-preserving SVDE. Moreover, we showed that a small amount of UTS data in the mixture is sufficient to train a geometry-preserving SVDE model; this opens new opportunities for using large-scale and diverse yet uncalibrated stereo data for geometry-preserving SVDE. Through performance tests, we demonstrated that GP2-trained SVDE models outperform the competitors not only in depth estimation accuracy but also in inference speed.
Link to the paper
References
[1] David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network, 2014.
[2] Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. In Computer Vision and Pattern Recognition (CVPR), 2018.
[3] René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12179–12188, October 2021.
[4] René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer, 2019.
[5] Wei Yin, Jianming Zhang, Oliver Wang, Simon Niklaus, Long Mai, Simon Chen, and Chunhua Shen. Learning to recover 3d scene shape from a single image. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn. (CVPR), 2021.

