AI
pMCT - Patched Multi-Condition Training
Introduction
The clashing of pans and pots as you cook and ask your voice assistant what you can use to replace eggs in the recipe. The excited, overlapping conversations as you ask which of Henry the VIIIs wives survived, trying to settle a bet. The low murmur of traffic and air conditioning as you drive and ask your voice assistant to play that song which has been stuck in your head for two days straight. Modern automatic speech recognition (ASR) models are fast becoming an integral way in which we interact with technology. This brings with it a notoriously difficult task -- we expect them to work perfectly in a huge range of environments, each with its unique acoustic challenges. While significant progress has been made in recent years to advance the state of the art, such as introduction of end-to-end transformer models (Gulati et al., 2020; Zhang et al., 2020) and use of ever-larger corpora via semi/self-supervised learning (van Engelen and Hoos, 2020; Park et al., 2020), robust speech recognition is still a challenge. Models trained on curated close-talk training datasets do not generalize well to real-world conditions, which often involve additive noise, channel distortion and reverberation (Tsunoo et al., 2021).
Considering the number and variety of acoustic conditions observed in real-world scenarios, acquisition of sufficiently diverse training data is not trivial, often leading to a mismatch between the train and test data distributions. Hence, as in many other domains of machine learning, data augmentation plays a crucial role in circumventing the issue.
In this blog, we present our work (Peso Parada et al., 2022) on data augmentation for robust speech recognition, pMCT - Patched Multi-Condition Training, which has been accepted at Interspeech 2022. It involves a simple but highly effective modification of a standard data augmentation approach, allowing us to train models which perform better in noisy and reverberant scenarios.
Motivation: Why Patches?
At the heart of this approach lies the notion of audio patches. We will begin by showing how this notion arises naturally from the manifold hypothesis, and consider how it can be used as an inductive bias to motivate novel data augmentation approaches.
Let’s suppose we have access to clean data, arising from some distribution  , with support
, with support  . We can assume that (1) there exists some alternative distribution
. We can assume that (1) there exists some alternative distribution  with a different support
with a different support 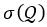 ; and (2) we have access to a procedure to efficiently sample from . It is important to note that does not need to be explicitly defined (e.g., through an explicit density). This alternative distribution may be implicitly defined by a dataset collected in these scenarios, or by a procedure that transforms samples from into ones from by suitably altering their structure, such as by audio modification of
; and (2) we have access to a procedure to efficiently sample from . It is important to note that does not need to be explicitly defined (e.g., through an explicit density). This alternative distribution may be implicitly defined by a dataset collected in these scenarios, or by a procedure that transforms samples from into ones from by suitably altering their structure, such as by audio modification of  to obtain a distorted speech signal
to obtain a distorted speech signal  .
.
Consider the entire signal space,  of dimensionality
of dimensionality  , on which all possible signals reside. According to the manifold hypothesis (Fefferman et al., 2016), we can assume that both the clean signals
, on which all possible signals reside. According to the manifold hypothesis (Fefferman et al., 2016), we can assume that both the clean signals  and distorted signals
and distorted signals  lie on a d dimensional manifold
lie on a d dimensional manifold 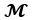 of
of  where
where  . More precisely, since manifolds can be approximated by locally Euclidean patches in small neighborhoods, phonemes and utterances reside on audio patches (Vaz et al., 2015). Hence, it follows that the support
. More precisely, since manifolds can be approximated by locally Euclidean patches in small neighborhoods, phonemes and utterances reside on audio patches (Vaz et al., 2015). Hence, it follows that the support  lies on
lies on  .
.
Manifold learning methods (Fefferman et al., 2016; Vaz et al., 2015) assume that speech does not exist in the remaining  dimensions. Accordingly, they aim to project noisy data onto noiseless subspaces, such as to the manifolds formed by the eigenvectors corresponding to the
dimensions. Accordingly, they aim to project noisy data onto noiseless subspaces, such as to the manifolds formed by the eigenvectors corresponding to the  largest singular values of noisy data (Dendrinos et al., 1991). We do not perform computationally complex projections from data space or the support on for noise removal. Instead, we consider other ways in which the inductive biases arising from the manifold hypothesis can be leveraged. Specifically, we note that data augmentation can be informative if the support of the distribution generated by data augmentation on is close to (Sinha et al., 2021).
largest singular values of noisy data (Dendrinos et al., 1991). We do not perform computationally complex projections from data space or the support on for noise removal. Instead, we consider other ways in which the inductive biases arising from the manifold hypothesis can be leveraged. Specifically, we note that data augmentation can be informative if the support of the distribution generated by data augmentation on is close to (Sinha et al., 2021).
Drawing on the above intuitions, we propose to train DNNs with data augmentation in the form of audio patches, approximating utterance manifolds. We hypothesize that this augmentation will improve robustness of ASR models against acoustic distortions.
Data Augmentation for Robust ASR
Above, we explored the intuitions for patch-based audio augmentations. Next, we will consider how they can be implemented. Multi-Condition Training (MCT) (Kim et al., 2017; Ko et al., 2017), also referred to as Multi-style TRaining (MTR) (Park et al., 2020) is a popular data augmentation approach used for improving performance in noisy and reverberant conditions. MCT typically applies Room Impulse Response (RIR) and additive noise to a clean audio sample as shown in Figure 1. Room Impulse Response refers to the shape the sound takes from the point it is generated to the point where it is captured. Simulating different RIRs allows for emulating the spectral shaping of sound created in different rooms.

Figure 1. Data augmentation following MCT
Formally, for a clean speech signal 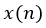 a modified speech signal
a modified speech signal 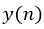 is obtained by first convolving the speech signal with a Room Impulse Response
is obtained by first convolving the speech signal with a Room Impulse Response  to introduce reverberation. Next, a noise source
to introduce reverberation. Next, a noise source  is added by
is added by

where  is the effective length of the Room Impulse Signal, , and
is the effective length of the Room Impulse Signal, , and 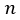 is the time index.
is the time index.

Figure 2. (a) Waveform of a clean speech signal of length  is split into patches
is split into patches  with length
with length  for
for  . (b) Noisy reverberant waveform , is simulated using (1), and split into patches
. (b) Noisy reverberant waveform , is simulated using (1), and split into patches  . (c) Augmented signal
. (c) Augmented signal  comprises segments from and . Vertical dashed lines indicate the size of each patch,
comprises segments from and . Vertical dashed lines indicate the size of each patch,  .
.
Our Approach: Patched Multi-Conditional Training (pMCT)
The differences between the original waveform, the MCT-generated waveform and our proposed Patched Multi-Conditional Training (pMCT) waveform are shown in Figure 2. We propose to adapt MCT as follows:
First, the patch extraction step is performed. To obtain the patches for pMCT, the signals and are split into patches  and
and  , respectively, each of size
, respectively, each of size  . It follows that
. It follows that  , where is the length of . Hence, the clean patches are given be
, where is the length of . Hence, the clean patches are given be  and the distorted patches by
and the distorted patches by  , where
, where  is the total number of patches. This is represented in Figure 3 by vertical dashed lines.
is the total number of patches. This is represented in Figure 3 by vertical dashed lines.
Next, patch mixing is executed as shown in Figure 3. The final augmented signal  is obtained by determining a patch
is obtained by determining a patch  as a clean patch
as a clean patch  with a probability
with a probability 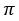 , or as a distorted patch
, or as a distorted patch  with the probability
with the probability  where := denotes the assignment operator. Each element
where := denotes the assignment operator. Each element 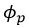 is the
is the 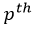 patch of the signal as shown in Fig.1(c). The delay of the RIR's direct path is removed in order to align the and so that they can be mixed.
patch of the signal as shown in Fig.1(c). The delay of the RIR's direct path is removed in order to align the and so that they can be mixed.

Figure 3. Flow diagram flow of the proposed Patched Multi-Conditional Training (pMCT)
Audio Examples

Figure 4. Examples of a recoding with the clean signal (top), the modified speech signal (middle) and the patched signal (bottom)
This file represents the top plot in Figure 4.
This file represents the middle plot in Figure 4.
This file represents the bottom plot in Figure 4.
Experimental Results
We refer the reader to our paper (Parada et al., 2022) for full experimental details and results.
We implemented the transformer recipe from SpeechBrain (Ravanelli et al., 2021) which implements an end-to-end transformer ASR model. It follows the Conformer configuration (S) outlined in (Gulati et al., 2020) and includes a transformer language model. The model was trained on LibriSpeech (Panayotov et al., 2015), a dataset derived from English audiobooks. In order to evaluate the effectiveness of our proposed approach, it was essential to evaluate on an acoustically challenging dataset. To this end, we employed VOiCES (Richey et al., 2018) – a dataset created by recording LibriSpeech utterances played in acoustically challenging conditions.
When evaluating our approach, we were primarily interested in answering the following questions:
1) Does pMCT improve over the standard MCT?
2) Is it beneficial to combine pMCT with other data augmentation approaches, such as SpecAugment?

Table 1. Results for models trained on the 960h dataset
Table 1 shows the Word Error Rate (WER) achieved on LibriSpeech and VOiCES when the model trained on 960hrs of LibriSpeech was exposed to different data augmentation procedures. We find that pMCT outperforms MCT on both, LibriSpeech and VOiCES. The improvement is especially significant on the VOiCES dataset, achieving a relative WER reduction of 23.1%, suggesting that our method is particularly effective for noisy, reverberant scenarios. Furthermore, we find that combining pMCT with other augmentation methods, such as SpecAugment has a synergistic effect, giving rise to overall best performance.
Conclusions
Modern ASR models face a challenging task – we require that they perform optimally even in difficult acoustic conditions. In this blog, we introduced our augmentation method, pMCT, which improves accuracy of ASR models by employing patch modifications in combination with MCT. The proposed method is simple to implement, and introduces negligible computational overhead without requiring additional data compared to MCT. Experimental analyses on LibriSpeech and VOiCES show that pMCT outperforms MCT in both clean and noisy reverberant conditions and further improvements can be achieved by combining pMCT with other augmentation schemes, such as SpecAugment.
Link to the paper
https://arxiv.org/abs/2207.04949References
[1] Gulati, J. Qin, C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, and R. Pang, “Conformer: Convolution-augmented transformer for speech recognition,” in Interspeech. ISCA, 2020, pp. 5036–5040
[2] Y. Zhang, J. Qin, D. S. Park, W. Han, C. Chiu, R. Pang, Q. V. Le, and Y. Wu, “Pushing the limits of semi-supervised learning for automatic speech recognition,” CoRR, vol. abs/2010.10504, 2020.
[3] J. E. van Engelen and H. H. Hoos, “A survey on semi-supervised learning,” Mach. Learn., vol. 109, no. 2, pp. 373–440, 2020
[4] D. S. Park, Y. Zhang, Y. Jia, W. Han, C. Chiu, B. Li, Y. Wu, and Q. V. Le, “Improved noisy student training for automatic speech recognition,” in INTERSPEECH. ISCA, 2020, pp. 2817–2821.
[5] E. Tsunoo, K. Shibata, C. Narisetty, Y. Kashiwagi, and S. Watanabe, “Data Augmentation Methods for End-to-End Speech Recognition on Distant-Talk Scenarios,” in Interspeech, 2021, pp. 301– 305
[6] P. P. Parada, A. Dobrowolska, K. Saravanan, M. Ozay, “pMCT: Patched Multi-Condition Training for Robust Speech Recognition, in Interspeech 2022
[7] C. Fefferman, S. Mitter, and H. Narayanan, “Testing the manifold hypothesis,” Journal of the American Mathematical Society, vol. 29, no. 4, pp. 983–1049, Oct. 2016
[8] C. Vaz and S. Narayanan, “Learning a Speech Manifold for Signal Subspace Speech Denoising,” in Interspeech, 2015, pp. 1735– 1739
[9] M. Dendrinos, S. Bakamidis, and G. Carayannis, “Speech enhancement from noise: A regenerative approach,” Speech Commun., vol. 10, no. 1, p. 45–67, Feb 1991.
[10] Sinha, K. Ayush, J. Song, B. Uzkent, H. Jin, and S. Ermon, “Negative Data Augmentation,” in ICLR, 2021
[11] C. Kim, A. Misra, K. Chin, T. Hughes, A. Narayanan, T. Sainath, and M. Bacchiani, “Generation of large-scale simulated utterances in virtual rooms to train deep-neural networks for far-field speech recognition in google home,” in Interspeech, 2017, pp. 379–383.
[12] T. Ko, V. Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in ICASSP, 2017, pp. 5220–5224.
[13] D. S. Park, Y. Zhang, C.-C. Chiu, Y. Chen, B. Li, W. Chan, Q. V. Le, and Y. Wu, “Specaugment on large scale datasets,” in ICASSP, 2020, pp. 6879–6883
[14] M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y. Gao, R. D. Mori, and Y. Bengio, “SpeechBrain: A general-purpose speech toolkit,” 2021, arXiv:2106.04624.
[15] A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, and R. Pang, “Conformer: Convolution-augmented Transformer for Speech Recognition,” in Interspeech, 2020, pp. 5036–5040.
[16] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an ASR corpus based on public domain audio books,” in ICASSP, 2015, pp. 5206–5210.
[17] C. Richey, M. A. Barrios, Z. Armstrong, C. Bartels, H. Franco, M. Graciarena, A. Lawson, M. K. Nandwana, A. Stauffer, J. van Hout, P. Gamble, J. Hetherly, C. Stephenson, and K. Ni, “Voices Obscured in Complex Environmental Settings (VOiCES) Corpus,” in Interspeech, 2018, pp. 1566–1570



