AI
Self-Supervised Accent Learning for Under-Resourced Accents Using Native Language Data
Motivation and Introduction
Last decade has seen a rise in the number and quality of neural networks based ASR models, for example the ability to process sequences [1] through recurrent neural networks (RNN) based encoder-decoder models, often using an attention [2] mechanism to preserve the context while training in an end-to-end (E2E) [3] manner. Wav2Vec2.0 [4] and other works like contextnet [5] have chosen to move away from the RNN-centric modeling of sequences, successfully relying on Transformers and convolutional neural networks (CNN), respectively.
The push towards self-supervised models [6] that learn hidden but meaningful representations from unlabeled audio [4], [7], [8], [9], and reduce dependence on large corpora of transcribed data, is particularly noteworthy. There has been a particular trend towards using less external supervision while pre-training ASR models using large amounts of unlabeled data [4], [9]. Self-supervised models or learning has been successfully extended to multi-lingual ASR [10], [11]. For example, wav2vec 2.0 [4] models for English are pre-trained with multilingual speech data as an obvious next step [11].
There has also been interest in improving ASR accuracy for accented speech [12], [13], [14], [15], [16]. Collecting labeled speech data from English speakers for various accents across the globe is a challenging and expensive task. In cases where labeled accented English data is not available, an iterative semi-supervised learning can be used to generate inaccurate labels using the existing recognizer [17]. However, these pseudo labels generated may be quite erroneous and the manual labeling or correction of this is highly tedious as well as expensive.
This blog explores the possibility of adapting a well-trained English model to targeted accents using unlabeled native language data collected from native speakers of the target accent or language groups. Collection of unlabeled native language speech for any accent including the under-resourced ones is easier and less expensive. Non-native English speakers are heavily influenced by the co-articulation of sounds in their own native language. We use this knowledge to adapt a well-trained English base model towards a target accent by pre-training it with the corresponding unlabeled native language data. A limited amount of labeled English data from the target accent is used to fine-tune the model to the target accent.
The use of native-language data during pre-training can reduce the amount of labeled accented English data required during the fine-tuning. It also improves the overall accuracy of the ASR model for the target accent for the same amount of the labeled data used during fine-tuning. The methods used in the other accented English ASR [12], [13], [18] systems are complementary to our efforts and they can be used in conjunction to achieve synergistic improvement in performance.
Self-supervised Learning for Accent Adaptation
In self-supervised methods that learn speech representations from a large pool of unlabeled data, one could start by pre-training (PT) the model using a pool of accent rich data for the target language, and later fine-tune (FT) the model using labeled data for the target accent. As compared to the fully supervised method, this approach can improve the performance for the target accent without the need for large amounts of labeled data for the accent. Also, when dealing with under-resourced accents of a language (say English) it may be difficult to find a set of representative speakers for that target accent, and even more difficult to label this data accurately. At the same time, collecting native language data for the target accent may not be as difficult.
Self-supervised Accent Learning From Native Language Data

Figure 1. Block schematic for self-supervised accent adaptation or learning.
In this blog, we propose to use unlabeled native language data to pre-train the model so that we can achieve better ASR accuracies for the same but limited amount of labeled accented data. The block schematic of our proposed approach is shown in Figure 1. The ASR model can be pre-trained from scratch by combing this native language data with the available English data from all possible accents including the target accent. Or when the ASR model is already trained or pre-trained and in use, we can do a controlled pre-training of the model using the unlabeled target accent data and/or native language data before we fine-tune the model with labeled targeted accent data. Our experiments focus on efficient use of resources while adapting an ASR model well-trained on the baseline task or primary English accent to a set of new target tasks, namely accented English speech. The baseline ASR model architecture can be any contemporary end-to-end sequence-to-sequence system with self-supervised training capabilities. The model should be capable of adapting to new speech data or scenario ideally using a small amount of labeled speech data.
Experimental Setup
We propose to use the transformer based Wav2Vec2.0 encoder architecture with a CTC decoder for all our experiments [4]. The models are capable of self-supervised training [19] and have close to state-of-the-art WER on LibriSpeech dataset. The model is pre-trained with the entire 960 hours of Librispeech dataset in a self-supervised manner to learn the speech representation from unlabeled data. From this model, we further pretrain with the targeted accent or native data for ∼150K updates. The pretrained models are finetuned for ∼320K updates with targeted accent. The language models or lexicons were not used to avoid a bias in the transcription. A barebones viterbi decoder was used which is available in fairseq [20]. These choices result in higher WERs in the presented results but a fairer comparison between the experiments. Default hyperparameters are used [20], except the learning rate.
Datasets
The data used in our experiments can be categorized into three main categories. The first category consists of the training data used for building a baseline model during the pre-training or representation learning stage. The complete 960 hours of LibriSpeech training data is used for training a baseline pre-trained model. The second category of data is for accent adaptation, and we use six different accents including American (enUS), British (enGB), Korean (enKR), Spanish (enSP), Chinese (enCH) and Indian (enIN). The duration of each of these labeled accented speech datasets used for fine-tuning is under 200 hours (50∼153 hours in Table 1). The third category of data is the native language data for learning the inherent influence on accented English spoken by these non-native English speakers. Similar to the accent adaptation, we use native British, Korean, Spanish, Mandarin-Chinese, and Indian language data for this purpose. British Native English and enGB are technically same, but we split it into accent and native data.

Table 1. Amount of accented and native language data used in our experiments.
Similarity Measure Between Accents
A similarity measure is derived based on a model’s performance on different accents when trained or finetuned to a particular accent as follows: Cij = (Wij − Wjj )/Wjj , where Cij denotes the similarity score and Wij denotes the word error rate of a model trained on accent i when tested on accent j. Higher the value of Cij , farther the accent from the model. Likewise, smaller the value, closer the accents i and j. For example, in Table 2, model trained on enCH and tested on enKR has CenCH, enKR = 1.31, as well as the converse CenKR, enCH = 1.03, which suggests that enCH training dataset can be augmented with enKR data, and vice versa. This measure can been used to select and restrict the fine-tuning as well as cross-training to improve the WER for multiple accents simultaneously. Also, note that Cij is not exactly same as Cji due to the nature and amounts of training and test data used. Among these, British English accent is the closest in terms of acoustic similarity to the American accent in Librispeech corpus, followed by Spanish, Korean, Indian, and Chinese accents - in that order, as presented in Table 2.
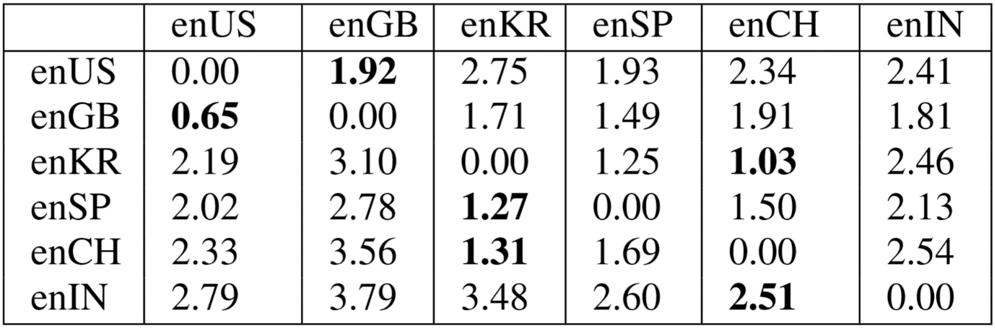
Table 2. Distance measure Cij where ith row represents the training accent data, jth column is the test accent data.
Experiments
We use the model size and architecture denoted as large in [4] as the baseline model for all our experiments. The baseline performance of the model when pre-trained using the 960h LibriSpeech data (denoted as Base or PT960h) and fine-tuned to target accents is given in Table 3.

Table 3. Performance (WER in %) of the baseline model PT960h when fine-tuned with different target accents (rows) and tested against all accents (columns).
It can be seen that targeted fine-tuning to a specific accent (diagonal entries) performs significantly better compared to the all other cases where there is a mismatch between the fine-tuned accent and the accent being evaluated. Starting with the base pre-trained model PT960h, we further pretrain the model using different combinations of unlabeled pre-train data: Target Accent (TarAcc), Target Native (TarNat), Target Accent and Target Native combined (TA + TN), All Accent - All accent data combined (AllAcc), All Native - All native data combined (AllNat) dataset. The performance of these models after the additional pre-training followed by fine-tuning to target accents is shown in Table 4.

Table 4. WERs of models pre-trained with different data before fine-tuning to the target accent.
It can be seen that the models perform significantly better (∼5-15%) in majority of the cases when either target accent or target native data is used during pre-training. Noticeably, the models trained with Target Native (T arNat) data performs marginally better (in the case of enKR and enCH) and similar (enSP) in accuracy than the models trained with Target Accent (TarAcc) data. This could be primarily due to the richness of sounds present in the native language that may get captured during pre-training. This shows that an accuracy similar or even better can be obtained just by pretraining using native language data rather than trying to find English speakers for each accent.
In order to study the effect of the amount of native language data used or required during pre-training, we reduce the native dataset to 10 hours. The results are shown in Table 5.

Table 5. Pre-training with 10hr native data.
In the case of Korean accent we see that there is a graded improvement from using 10 hours (Table 5) of native Korean data to 50 hours (Table 4). However, the results for Spanish and Chinese accents show that the models pretrained with as little as 10 hours of native data can perform as good as using ∼100 hours of native data. To see the effectiveness of targeted native/accent data, we conduct experiments with mismatched native/accent data during pretrain and fine-tune.

Table 6. Fine-tuning to enSP with different pre-training data.
In Table 6, we further pre-train the base PT960h model using Mandarin-Chinese (mdCH), Chinese-English (enCH), native Great Britain English (denoted gbGB to distinguish it from the enGB dataset used as target accent data for fine-tuning) before fine-tuning it with enSP (English with accented Spanish) data. As expected, the mismatch of native/accent data between PT and FT (bottom 3 rows) makes the accuracy worse than the matched cases (top 6 rows). Nevertheless, despite the mismatch, use of additional pre-training data improves the performance compared to the enUS Baseline model.

Table 7. WERs for enGB accented models.

Table 8. WER for Chinese English (enCH) accented models.
In order to study the effect of one native language or accent on the other accents, we present the results for enGB (Table 7) and enCH (Table 8) models (with matched PT and FT) on other accents. It can be seen from Table 7 that the use of different sets of data during PT (gbGB) and FT (enGB) gives a significant improvement for all accents. However, surprisingly using the same enGB target accent data during both PT and FT improves the accuracy for enGB but degrades performance for all other accents. A similar observation can be made from results in Table 8. Also, results from Table 8 show that pre-training with mdCH and fine-tuning with enCH improves the accuracies for Korean and Spanish accents, correlating well with the distance values shown in Table 2.
Discussions
Some of the key observations from our experiments are as follows: 1. Accent adaptation of a self-supervised baseline model by additional pre-training using native language data followed by a finetuning using target accent data yields the best results for each target accent, in terms of amount of data required and the improvements in accuracies. 2. Using a small amount of native language data during pre-training performs better as compared to using the same fine-tuning target accent data for pre-trained model adaptation. 3. The use of as small as 10h of targeted native language data during pre-training can give accuracies similar to that of using ∼100h of native language data or several hundreds of hours of multi-lingual data. 4. Pre-training and fine-tuning with one matching target native language and accent data improves WER on other accents depending on the distance measure Cij .
Conclusions
In this blog, we demonstrate that low-resource self-supervised accent adaptation and fine-tuning are both viable for accented English ASR systems. A controlled adaptation of a pre-trained high-resource accent model is possible for low-resource accents using two different ways. One is to use the fine-tuning accented data for targeted adaptation of pre-trained model. Another option is to use native language data corresponding to the target accent for adapting the pre-trained model. The second option is better than the first as the model sees new data apart from what is used for fine-tuning.
Link to the paper
Mehul Kumar, Jiyeon Kim, Dhananjaya Gowda, Abhinav Garg, Chanwoo Kim. Self-Supervised Accent Learning for Under-Resourced Accents Using Native Language Data. ICASSP. 2023.
Paper link : https://ieeexplore.ieee.org/document/10096854References
[1] Ilya Sutskever, Oriol Vinyals, and Quoc V Le, “Sequence to sequence learning with neural networks,” in Advances in neural information processing systems, 2014, pp. 3104–3112.
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
[3] Chanwoo Kim, Sungsoo Kim, Kwangyoun Kim, Mehul Kumar, Jiyeon Kim, Kyungmin Lee, Changwoo Han, Abhinav Garg, Eunhyang Kim, Minkyoo Shin, et al., “End-to-end training of a large vocabulary end-to-end speech recognition system,” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 562–569.
[4] Alexei Baevski, Yuhao Zhou, Abdel-rahman Mohamed, and Michael Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in Neural Information Processing Systems, vol. 33, 2020.
[5] Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, ChungCheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, and Yonghui Wu, “Contextnet: Improving convolutional neural networks for automatic speech recognition with global context,” arXiv preprint arXiv:2005.03191, 2020.
[6] Ian Tenney, Dipanjan Das, and Ellie Pavlick, “Bert rediscovers the classical nlp pipeline,” arXiv preprint arXiv:1905.05950, 2019.
[7] Gabriel Synnaeve, Qiantong Xu, Jacob Kahn, Edouard Grave, Tatiana Likhomanenko, Vineel Pratap, Anuroop Sriram, Vitaliy Liptchinsky, and Ronan Collobert, “End-to-end asr: from supervised to semi-supervised learning with modern architectures,” arXiv preprint arXiv:1911.08460, 2019.
[8] Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021.
[9] A. Baevski and A. Mohamed, “Effectiveness of self-supervised pre-training for asr,” in ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 7694–7698.
[10] Jama Hussein Mohamud, Lloyd Acquaye Thompson, Aissatou Ndoye, and Laurent Besacier, “Fast development of asr in african languages using self supervised speech representation learning,” 2021.
[11] Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert, “Mls: A large-scale multilingual dataset for speech research,” arXiv preprint arXiv:2012.03411, 2020.
[12] Song Li, Beibei Ouyang, Dexin Liao, Shipeng Xia, Lin Li, and Qingyang Hong, “End-to-end multi-accent speech recognition with unsupervised accent modelling,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6418–6422.
[13] Peter Bell, Joachim Fainberg, Ondrej Klejch, Jinyu Li, Steve Renals, and Pawel Swietojanski, “Adaptation algorithms for neural network-based speech recognition: An overview,” IEEE Open Journal of Signal Processing, vol. 2, pp. 33–66, 2020.
[14] Felix Weninger, Yang Sun, Junho Park, Daniel Willett, and Puming Zhan, “Deep learning based mandarin accent identification for accent robust asr.,” in INTERSPEECH, 2019, pp. 510–514.
[15] Hu Hu, Xuesong Yang, Zeynab Raeesy, Jinxi Guo, Gokce Keskin, Harish Arsikere, Ariya Rastrow, Andreas Stolcke, and Roland Maas, “Redat: Accent-invariant representation for end-to-end asr by domain adversarial training with relabeling,” 2021.
[16] Xuesong Yang, Kartik Audhkhasi, Andrew Rosenberg, Samuel Thomas, Bhuvana Ramabhadran, and Mark HasegawaJohnson, “Joint modeling of accents and acoustics for multiaccent speech recognition,” in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 1–5.
[17] Daniel S Park, Yu Zhang, Ye Jia, Wei Han, Chung-Cheng Chiu, Bo Li, Yonghui Wu, and Quoc V Le, “Improved noisy student training for automatic speech recognition,” arXiv preprint arXiv:2005.09629, 2020.
[18] MA Tugtekin Turan, Emmanuel Vincent, and Denis Jouvet, ˘ “Achieving multi-accent asr via unsupervised acoustic model adaptation,” in INTERSPEECH 2020, 2020.
[19] Alexei Baevski, Michael Auli, and Abdelrahman Mohamed, “Effectiveness of self-supervised pre-training for speech recognition,” arXiv preprint arXiv:1911.03912, 2019.
[20] Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli, “fairseq: A fast, extensible toolkit for sequence modeling,” in Proceedings of NAACL-HLT 2019: Demonstrations, 2019.





