AI
[CVPR 2023 Series #1] SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields
|
The Computer Vision and Pattern Recognition Conference (CVPR) is a world-renowned international Artificial Intelligence (AI) conference co-hosted by the Institute of Electrical and Electronics Engineers (IEEE) and the Computer Vision Foundation (CVF) which has been running since 1983. CVPR is widely considered to be one of the three most significant international conferences in the field of computer vision, alongside the International Conference on Computer Vision (ICCV) and the European Conference on Computer Vision (ECCV). In this relay series, we are introducing a summary of the 6 research papers at the CVPR 2023 and here is a summary of them. - Part 1 : SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields (by Samsung AI Center – Toronto) - Part 3 : GENIE: Show Me the Data for Quantization (by Samsung Research) |
Introduction and Motivation
Smartphones have enabled unprecedented accessibility to cameras and images; in conjunction with social media, content creation (e.g., images and videos) has never been more popular. This boom has been accompanied by increasing interest in AI-assisted image manipulation, such as editing out unwanted objects and adding video effects based on tracking. But something is missing from these applications – they do not capture the 3D nature of the world. Imagine users who want to capture a scene, so it can be viewed from another perspective later. It could be a place they want to virtually walk through, or perhaps they would simply like to see their own face from a new angle. Neural Radiance Fields (NeRFs) have provided an approach to realizing this capability: given a set of images (e.g., taken by a smartphone), a NeRF enables constructing new images of the captured scene from previously unseen angles. As NeRFs grow in popularity and accessibility, we expect a growing demand for manipulating them, just as has occurred for 2D images and videos.
Yet, such operations are more difficult in 3D than in 2D. We focus on one particular manipulation: object removal and inpainting in 3D. This blog describes our approach to this problem, starting from identifying a target object with a simple 2D user interface and ending with a manipulated NeRF, which realistically represents the full 3D scene without the target object. We found that our method yields unprecedented performance on this relatively new task of 3D scene alteration, and it is able to generate much more realistic images from novel views than contemporary approaches. Figure 1 provides an overview of our model.

Figure 1. An example of the inputs and outputs of our 3D inpainting framework. In addition to the images captured from the scene and their automatically recovered camera parameters, users are tasked with providing a few points in a single image to indicate which object they wish to remove from the scene (upper-left inset). These sparse annotations are then automatically transferred to all other views and utilized for multiview mask construction (upper-right inset). The resulting 3D-consistent mask is used in a perceptual optimization problem that results in 3D scene inpainting (lower row), with rendered depth from the optimized NeRF shown for each image as an inset.
Neural Radiance Fields
NeRFs [1] provide a mechanism for turning sets of images into complete 3D scene representations via neural networks. Given images  to
to  , camera parameters (i.e., the properties of the camera, such as its position and orientation) for each image are inferred with standard computer vision techniques [2]:
, camera parameters (i.e., the properties of the camera, such as its position and orientation) for each image are inferred with standard computer vision techniques [2]:  to
to  . Then, a learning process is undertaken, which results in a trained neural network, R, capable of novel view synthesis (NVS). Effectively, R is a realistic 3D renderer: given any new camera
. Then, a learning process is undertaken, which results in a trained neural network, R, capable of novel view synthesis (NVS). Effectively, R is a realistic 3D renderer: given any new camera  (i.e., 3D viewpoint), a realistic image is generated for that viewpoint, simply understood as
(i.e., 3D viewpoint), a realistic image is generated for that viewpoint, simply understood as  . This is an optimization process, where the network simply learns to reconstruct the given images, when rendering from their associated camera viewpoints. Internally, in order to perform NVS, the NeRF learns a rich and detailed 3D representation of the scene. Geometrically, a representation of scene depth can also be rendered from a NeRF (i.e., we can obtain a depth image
. This is an optimization process, where the network simply learns to reconstruct the given images, when rendering from their associated camera viewpoints. Internally, in order to perform NVS, the NeRF learns a rich and detailed 3D representation of the scene. Geometrically, a representation of scene depth can also be rendered from a NeRF (i.e., we can obtain a depth image  for any image
for any image  ). Our work focuses on altering the training process of the NeRF, modifying the 3D scene based on the user-designated target that we wish to remove. When rendered from any view, the resulting model no longer contains the unwanted object.
). Our work focuses on altering the training process of the NeRF, modifying the 3D scene based on the user-designated target that we wish to remove. When rendered from any view, the resulting model no longer contains the unwanted object.
Multiview Segmentation
In order to remove an entity, we first need to be able to identify it. For this, we turn to multiview segmentation (MVSeg) techniques, which attempt to “segment out” a common object shared across a set of images. Specifically, for each image  , an object mask
, an object mask  is constructed that covers the target object. The combined set of masks across all images provides a 3D “hull” around the target object. Our identification method focuses on both accuracy and user ease-of-use: we want to be able to capture the details of the target, as this reduces the burden on the downstream inpainter, but we also wish to minimize the strain on the user, ideally asking them to do as little and as simple work as possible. In particular, it is preferable to only ask the user to identify the object in only one image and propagate it to multiple views automatically, as it reduces user effort and prevents clashes that might arise with inconsistent annotations across multiple images. We use the set of MVSeg masks to identify the unwanted object, allowing an inpainting model to remove it.
is constructed that covers the target object. The combined set of masks across all images provides a 3D “hull” around the target object. Our identification method focuses on both accuracy and user ease-of-use: we want to be able to capture the details of the target, as this reduces the burden on the downstream inpainter, but we also wish to minimize the strain on the user, ideally asking them to do as little and as simple work as possible. In particular, it is preferable to only ask the user to identify the object in only one image and propagate it to multiple views automatically, as it reduces user effort and prevents clashes that might arise with inconsistent annotations across multiple images. We use the set of MVSeg masks to identify the unwanted object, allowing an inpainting model to remove it.
Inpainting 2D Images
Object removal and inpainting in 2D is among the most useful and widely used image alterations, popularized to the extent that “photoshopping” is a common colloquialism. Consequently, it is also one of the most well-researched topics in computer vision and graphics, with a history spanning decades [3]. The current state-of-the-art models, based on deep neural networks, generate a new inpainted image, from an input image and a mask identifying an unwanted target. In many cases, a modern inpainted image can be nearly indistinguishable from a plausible, real image.
However, existing methods operate purely in 2D: they cannot inpaint a multiview set of images in a consistent manner, nor can they be applied directly to a 3D representation like a NeRF. Indeed, the naïve approach to multiview inpainting (i.e., simply inpainting each independently) fails, due to view inconsistency – differences in the views induce differences in their inpaintings, which may or may not be subtle (even if the inpainter is deterministic). When the NeRF attempts to combine these inconsistent images, the result is blurry or otherwise visually damaged. For instance, consider a set of images of a brick pattern, each independently inpainted, and trying to combine them together into a single image: instead of getting a realistic brick pattern, a blurry smear is generated instead. As such, a primary contribution of our technique is a way to apply these powerful 2D inpainters to this fundamentally 3D problem, while avoiding the issue of 3D inconsistency. The key to this achievement is the use of a perceptual metric, which we describe next. Figures 2 and 3 illustrate a toy example for comparing the MSE loss with the perceptual loss in a simple 2D case.

Figure 2. A sample grid pattern (left inset) is inpainted according to a square mask (middle inset) to generate 16 different inpaintings. These 16 inpaintings are inconsistent in the masked region, but all provide a convincing potential inpainted result.

Figure 3. As a toy example of the difference between the effect of using the perceptual loss compared to the MSE loss, we used 16 different inpainted imaged of the grid pattern to supervise an image output. In the left inset, we optimized the output to minimize the MSE loss, while in the right output, we fitted the output image with respect to the perceptual loss. As evident in the results, the inconsistent supervising images have led to a blurry output with MSE loss, while using the perceptual loss has led to a sharper optimized texture in the masked region.
Perceptual Image Metrics
An image is commonly represented as a matrix of pixel values. It is therefore simple to compute the difference between two images in a pixelwise manner, by just looking at the difference between each entry of the two matrices. However, this kind of “distance” between images has significant drawbacks, one of which is poor correlation to the perceptual difference experienced by humans. For example, a small spatial shift of an image may end up having a large pixelwise distance to the unshifted original image; yet, to a person, the two images would be visually nearly identical (i.e., low perceptual distance). To combat this, more sophisticated image metrics have been devised, including perceptual metrics. The most common perceptual metrics utilize the distances between features, derived from neural networks, instead of the distances between pixels. In our case, the Learned Perceptual Image Patch Similarity (LPIPS) [4] distance metric is applied. In contrast to a pixelwise metric, which causes blur when averaging two inconsistent patches in colour pixel space, using LPIPS to average such patches (in the perceptual space) can still yield a sharp and realistic texture.
Background: Neural Radiance Fields
Neural Radiance Fields (NeRFs) have emerged as the state-of-the-art novel view synthesis methods. Given multiple 2D images of a static scene, a NeRF encodes the scene as a mapping between 3D coordinates and view directions to a view-dependent color and a view-independent density. The density is proportional to the probability of a point blocking a ray passing through it (one can think of it as the opacity of the point). The scene is rendered according to this differentiable model via the volumetric rendering equation. Using 2D captures of the scene, renders of the NeRF model are compared to the training views to fit the NeRF model and optimize it to generate the training views. After optimization, the same NeRF can be used to render previously unseen views of the scene (views other than the ones in the training dataset). For more information on NeRFs, please refer to www.matthewtancik.com/nerf.
Our pipeline
The input to our method is (A) a set of images (as well as their camera parameters, which can be readily obtained through automated means) and (B) a minimal set of user annotations on one image, identifying the target object (for which a few touches or clicks usually suffices). The output is a NeRF representation of the 3D scene captured by the image set, without the identified object. This representation can then be used for realistic NVS (e.g., viewing the scene from new perspectives, or generating videos via virtual camera trajectories in the scene).
Our pipeline consists of two main tasks: (i) selection of the target entity for removal and (ii) construction of the 3D-inpainted NeRF without that target.
Object Selection
To ease the burden on the user, we present only a single image, say  , from the set to him or her. The user then simply touches (or clicks on, depending on the user interface) the unwanted object in a few places. We must take these sparse annotations (points on one image) and construct a full 3D mask (i.e., a mask for every image in the set). We first obtain a rough “source” mask (
, from the set to him or her. The user then simply touches (or clicks on, depending on the user interface) the unwanted object in a few places. We must take these sparse annotations (points on one image) and construct a full 3D mask (i.e., a mask for every image in the set). We first obtain a rough “source” mask ( ) by applying existing techniques for interactive segmentation [5] on , yielding an initial estimate for , which we then propagate across the image set with a video segmentation model [6]. However, these models are not 3D-aware (meaning masks may not be consistent across the views) nor is the image set necessarily a video, meaning the model may make mistakes due to missing spatiotemporal cues. To correct this, we utilize a “semantic” NeRF fit to the images and their masks, such that “renders” from this NeRF actually provide a high-quality mask (not just colour) from any 3D viewpoint. Rendering from the semantic NeRF generates precise and 3D consistent masks across the image set (i.e., performs MVSeg) for use in inpainting. Note that the semantic NeRF fitting process can be repeated, but initialized with the improved masks instead of those from the video model – we call this our “two-stage” model. The top row of Figure 1 contains an example of the inputs and the process of our interactive 3D segmentation method.
) by applying existing techniques for interactive segmentation [5] on , yielding an initial estimate for , which we then propagate across the image set with a video segmentation model [6]. However, these models are not 3D-aware (meaning masks may not be consistent across the views) nor is the image set necessarily a video, meaning the model may make mistakes due to missing spatiotemporal cues. To correct this, we utilize a “semantic” NeRF fit to the images and their masks, such that “renders” from this NeRF actually provide a high-quality mask (not just colour) from any 3D viewpoint. Rendering from the semantic NeRF generates precise and 3D consistent masks across the image set (i.e., performs MVSeg) for use in inpainting. Note that the semantic NeRF fitting process can be repeated, but initialized with the improved masks instead of those from the video model – we call this our “two-stage” model. The top row of Figure 1 contains an example of the inputs and the process of our interactive 3D segmentation method.
3D Inpainting
Given the MVSeg masks, we now have corresponding images, masks, and camera parameters  . First, we inpaint every image with a modern single-image 2D inpainting model [7]:
. First, we inpaint every image with a modern single-image 2D inpainting model [7]:  . As discussed above, this means the inpainted images are 3D inconsistent; however, this will be rectified by our use of LPIPS.
. As discussed above, this means the inpainted images are 3D inconsistent; however, this will be rectified by our use of LPIPS.
We then modify the optimization process for learning NeRFs in two primary ways, as follows. First, when reconstructing an image, we treat unmasked and masked (now inpainted) regions differently. In the former case, we use the standard pixelwise approach to reconstruction. However, in the latter case, we use LPIPS, which enables us to bypass artifacts that the 3D inconsistency would normally cause. The second change deals with the 3D scene geometry, rather than its appearance or colours. Due to the inconsistencies between differently inpainted frames, the NeRF may learn to construct an unrealistic scene. We therefore utilize inpainted depth images as well. This can be done by (1) fitting a separate NeRF to the scene with the object (i.e., no masks), (2) rendering depth maps 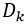 for each viewpoint, and (3) inpainting each via the mask
for each viewpoint, and (3) inpainting each via the mask  (generally, inconsistencies among depth inpaintings are far less consequential than for colour). Using these inpainted depth values provides 3D-consistent geometric supervision for our inpainted NeRF. The final inpainted NeRF faithfully represents the full 3D scene, with better quality than naïve approaches to 3D inpainting and often with comparable quality to having taken images of the scene without the object in the first place. We demonstrate this empirically below. Please refer to Figure 4 for an overview of our 3D inpainting method.
(generally, inconsistencies among depth inpaintings are far less consequential than for colour). Using these inpainted depth values provides 3D-consistent geometric supervision for our inpainted NeRF. The final inpainted NeRF faithfully represents the full 3D scene, with better quality than naïve approaches to 3D inpainting and often with comparable quality to having taken images of the scene without the object in the first place. We demonstrate this empirically below. Please refer to Figure 4 for an overview of our 3D inpainting method.

Figure 4. Overview of our inpainting method.
A New Evaluation Dataset
Using NeRFs for 3D inpainting is a very new field. As such, we provide a dataset of scenes that can be used to evaluate the NeRF inpainting task. To act as a benchmark, each scene requires two sets of images: one with an unwanted object, and one without it. The outputs of a 3D inpainting model fit using the first set can then be evaluated by its similarity to the second set, which can be considered a “ground-truth” (GT) image set. Human-annotated masks are also provided, to separate out the effect of using automated means to obtain masks (such as our MVSeg approach). We use this new dataset to test our model against competing techniques below. Figure 5 contains sample scenes from our dataset.

Figure 5. Sample scenes from our dataset. Columns: input view (left), corresponding target object mask (middle), and a ground-truth view without the target object, from a different camera pose (right). Rows: different scenes; see supplement for examples of all scenes.
Results and Impact
We evaluate both MVSeg (i.e., target object identification) and 3D inpainting results experimentally. For more in-depth results and analyses, we refer the reader to our paper (https://arxiv.org/abs/2211.12254).
For MVSeg, our baselines include a video segmentation model, several NeRF-based approaches that differ from our method, and two methods that operate only in 2D. When evaluating on the task of source mask propagation to other views, our method outperforms all other algorithms. Qualitative and quantitative results are shown in Figure 6 and Table 1, respectively.

Figure 6. A qualitative comparison of our multiview segmentation model against Neural Volumetric Object Selection (NVOS), video segmentation, and the human-annotated masks (GT).

Table 1. Quantitative evaluation of multiview segmentation modes, for the task of transferring the source mask to other views.
For 3D inpainting, we compare to a variety of approaches. “LaMa (2D)” [7] inpaints as a post-processing step: a NeRF is fit to the scene with the object, and then renders from that scene are masked and inpainted. “Masked NeRF” simply trains a NeRF but ignores anything that is masked; this tends to result in unconstrained behaviour in the masked areas. “Object NeRF” uses the 3D mask to effectively delete the 3D points within the mask hull, but again does not explicitly inpaint newly unveiled regions after object removal. Most similar to us is NeRF-In [8], which uses a pixelwise loss instead of a perceptual one, among other distinctions. Note that NeRF-In has two variants: using all images to supervise the masked region (providing information from many viewpoints, but at the expense of consistency), and using only one image (avoiding conflicts due to inconsistencies, but missing information from multiple view directions).
Evaluation proceeds by comparing novel views (i.e., renders from viewpoints unseen in training) from the inpainted NeRF to renders of the scene using the real images of the scene without the object (i.e., using the set of GT images from our dataset). Two image metrics are used: LPIPS (described above) and FID (which compares the statistical moments of two sets of images or renders). Both distance measures are designed to be robust to differences in exact pixel value, and instead consider perceptual similarity. This is important for inpainting, as there are an infinite number of plausible solutions for a given image, and comparing exact pixel colours can therefore be misleading when our goal is actually realism, rather than reconstruction. Please refer to Figure 7 for qualitative results, and Table 2 for quantitative evaluation of our 3D inpainting method against the baselines.

Figure 7. Visualizations of our view-consistent inpainting results.
Video 1. Demo video of Figure 7

Table 2. Quantitative evaluation of our inpainting method using human-annotated object masks.
Altogether, our results show that it is possible to provide an accessible interface for NeRF inpainting. Given a set of images, not only can a user trivially identify an unwanted object with a few touches on a single image, but the resulting NeRF can show impressive results in its inpainted renders. As 3D data and representations, such as NeRFs, become increasingly popular and obtainable on mobile devices (particularly smartphones), we hope our work can serve as a foundation for how to alter NeRFs in an efficient, visually appealing, and user-friendly manner.
|
About Samsung AI Center – Toronto The Samsung AI Research Center, in Toronto, was established in 2018. With research scientists, research engineers, faculty consultants, and MSc/PhD interns, its broad mission is to develop core AI technology that improves the user experience with Samsung devices. One research interest at SAIC-Toronto is the development of core tech related to new user experiences and image-related applications enabled by AI, especially related to images gathered by smartphone cameras. One recent application is 3D image manipulation, increasingly popularized by modern advances in neural methods for 3D scene representations. Below, we describe a novel pipeline that operates on a set of images of a scene (e.g., from a Samsung smartphone), followed by the construction of a 3D representation of that scene with any unwanted entities removed. In particular, it enables users to (i) identify unwanted objects in a single image with a few simple screen touches, followed by (ii) the generation of a 3D representation, which can be viewed by the user from any viewpoint, with the identified objects removed and the background realistically filled in. This work will be presented at CVPR 2023. |
Link to the paper
https://arxiv.org/abs/2211.12254References
[1] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
[2] Johannes Lutz Schonberger, and Jan-Michael Frahm. Structure-from-Motion Revisited. In CVPR, 2016.
[3] Jireh Jam, Connah Kendrick, Kevin Walker, Vincent Drouard, Jison Gee-Sern Hsu, and Moi Hoon Yap. A comprehensive review of past and present image inpainting methods.
[4] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric.
[5] Yuying Hao, Yi Liu, Zewu Wu, Lin Han, Yizhou Chen, Guowei Chen, Lutao Chu, Shiyu Tang, Zhiliang Yu, Zeyu Chen, and Baohua Lai. Edgeflow: Achieving practical interactive segmentation with edge-guided flow. In ICCV Workshops, 2021.
[6] Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
[7] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with Fourier convolutions. In WACV, 2022.
[8] Hao-Kang Liu, I-Chao Shen, and Bing-Yu Chen. NeRF-In: Free-Form NeRF Inpainting with RGB-D Priors. ArXiv, 2022. https://arxiv.org/abs/2206.04901
