AI
[CVPR 2023 Series #5] MobileVOS: Real-Time Video Object Segmentation Contrastive Learning Meets Knowledge Distillation
|
The Computer Vision and Pattern Recognition Conference (CVPR) is a world-renowned international Artificial Intelligence (AI) conference co-hosted by the Institute of Electrical and Electronics Engineers (IEEE) and the Computer Vision Foundation (CVF) which has been running since 1983. CVPR is widely considered to be one of the three most significant international conferences in the field of computer vision, alongside the International Conference on Computer Vision (ICCV) and the European Conference on Computer Vision (ECCV). In this relay series, we are introducing a summary of the 7 research papers at the CVPR 2023 and here is a summary of them. - Part 3 : GENIE: Show Me the Data for Quantization (by Samsung Research) - Part 5 : MobileVOS: Real-Time Video Object Segmentation Contrastive Learning Meets Knowledge Distillation (By Samsung R&D Institute United Kingdom) |
Background
Video Object Segmentation (VOS) is an important problem in computer vision and it has a lot of interesting applications like video editing, surveillance, autonomous driving, and augmented reality. Basically, VOS is when you try to find and follow objects across multiple frames in a video. However, in this particular work, we focus on semi-supervised VOS (SVOS), where you only get a description of the object in the first frame. SVOS is especially difficult because you have to be able to deal with things like other objects getting in the way or moving around, all while performing well in a class-agnostic manner.
When it comes to semi-supervised VOS (SVOS), there are three main ways to do it: online fine-tuning, object flow, and offline matching. Recently, people have been using memory-based methods [6, 5, 3], which are where you store previous frames in a memory bank and then use them to predict the next object masks [6, 5]. These methods are really good at finding feature correspondences, but they have a problem: they incur a significant memory overhead. Some people have tried to solve this problem by only storing a few frames [2], only working on keyframes [7], or even proposing a complex overhaul of the memory model itself [1, 4]. But even though these methods are really accurate and fast on high-end computers, they are too large and expensive to work in real-time on regular phones. So in this research, we introduce a new approach called MobileVOS, which is a set of high-performing and efficient models that work on phones thanks to a novel distillation loss.

Figure 1. MobileVOS can be used for real-time image in-painting on mobile phones.
Our contributions can be summarized as follows: 1.) We introduce a new loss function that combines knowledge distillation and supervised contrastive learning to address the gap between large and small memory models. We propose a boundary-aware pixel sampling strategy that further improves results and model convergence. 2.) By using this unified loss, we demonstrate that a standard network design can achieve performance comparable performance to state-of-the-art models while being up to 5x faster and having 32x fewer parameters. 3.) The proposed loss function enables real-time performance (30FPS+) on mobile devices like the Samsung Galaxy S22 without the need for complex architectural or memory design changes, while still maintaining competitive performance with state-of-the-art models.


Figure 2. MobileVOS is also shown to work well on domains very different from which it is trained.

Figure 3. The proposed student-teacher framework using boundary-aware distillation.
The teacher model utilises infinite memory, whereas the student model only retains memory from the previous and first frames/mask. The distillation from infinite memory encourages the student to learn features which are consistent and robust across multiple frames. Similarly, the auxiliary supervised contrastive objective encourages discriminative pixel-wise features around the boundary of objects.
Method
In this work, we proposes to use a pixel-wise representation distillation loss to transfer the structural information between two models. More concretely, we use a pre-trained infinite memory model as the teacher and a small finite memory model as the student. Both models are then fed the same augmented frames and a distillation loss is applied between them. This loss involves constructing correlation matrices from the two sets of representations, where each matrix captures the relationship between all pairs of pixels.
The representations, denoted as Cs and Ct, are chosen to be directly before the final point-wise convolution and upsampling layers. The final representation loss is then derived using an improved distance metric for distillation tasks:

An interesting property of this loss formulation is that it is equivalent to maximising the pixel-wise mutual information between the student and teacher.
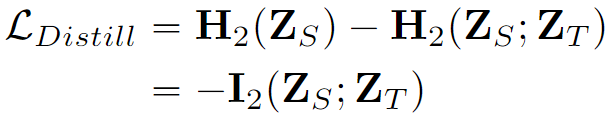
where H2 and I2 are matrix-based estimators resembling Renyi’s entropy and mutual information of order 2 respectively.
Unification with Contrastive Learning
The effectiveness of knowledge distillation alone can be dependant on the relative capacity gap between the student and teacher models. More formally, this training regime scales poorly as the capacity gap diminishes. To address this constraint, we propose a generalisation of our loss to encompass pixel-wise contrastive learning. Since we already have the dense ground truth classes, we can construct an additional target correlation matrix as follows:

where Y are the spatially-downsampled, one-hot-encoded labels for the 2 classes (object and background). We can then couple the two target correlation matrices to provide a way of interpolating between these two training regimes.

By considering a representation Z and the case where ω=0, the loss will now reduce to a familiar supervised contrastive learning (SCL) setting.

Intuitively, for a given pixel, the numerator attracts the positives, while the denominator repels the negatives. The connection between these two regimes is illustrated in the following diagram:

where the choice of ω is motivated by the availability and relative performance of a pre-trained teacher model.
Boundary-Aware Sampling
The majority of prediction errors occur on the edges of objects, and constructing a correlation matrix for all pixels is computationally intensive. In response to these challenges, we proposes a sampling strategy that only selects pixels around and near the edges of objects. This strategy restricts the distillation gradients to pixels that lead to prediction errors while making the formulation more computationally efficient. The normalization term will now averages over the size of the object boundaries, which enables the loss to equally weight both small and large objects. Furthermore, we observed that this modification has the added benefit of improving the overall model convergence.
Experiments
We provide an extensive evaluation of our proposed MobileVOS models and distillation pipeline on both the DAVIS and YouTubeVOS benchmarks. We also include a comprehensive re-evaluation of recent works in the literature regarding their latency and memory requirements, to demonstrate the improved performance in practise. To confirm the theoretical motivation, we qualitatively demonstrate that our distillation loss is encouraging more temporally robust features and finally show the generalisability of these models to out of domain videos, image-inpainting and on device segmentation.
DAVIS and YouTubeVOS Benchmarks
Our main comparison is with RDE-VOS[2], which proposes a dynamic memory update model to enable more efficient feature matching. We consider two different key encoder backbones, namely a ResNet18 and a MobileNetV2. For the MobileNetV2 model, we also show results with and without ASPP. Since the ResNet architectures achieve close to the original STCN performance, we choose to use a purely contrastive loss i.e. ω=0.0. This helps avoid overfitting to the teacher’s predictions on known classes and improve its generalisation to the unknown classes on YouTube. In contrast, for the much smaller MobileNet architectures, we use ω=0.95. These much smaller models are unlikely to overfit, and thus can benefit more from the distillation objective. It is worth noting that, in all cases, the models are also jointly trained with logit distillation, where τ=0.1.
We compare MobileVOS against previous state-of-the-art methods on the DAVIS 2017 validation split. The results are shown in the following table, in which our best performing model outperforms STCN by 0.3 J&F, while being just 0.2 shy of RDE-VOS, despite running 4× and 3× faster than these models, respectively. Additional experiments on DAVIS 2017 and YouTubeVOS can be found in our original paper.

Table 1. Results on the DAVIS 2017 validation set. CC denotes constant cost during the inference. FPS was averaged over 3 runs.
Model Size and Inference Latency
To conduct a fair comparison of the computational cost of previous works, we provide an extensive evaluation of MobileVOS and other methods on the same set of hardware. We consider both a server-grade NVIDIA A40 and a desktop-grade NVIDIA 1080Ti. In all cases, we use the authors’ provided code, but with a modification to accept randomly generated video sequences of two different durations. The results can be seen in the following table and show that our MobileVOS models are significantly smaller, while retaining a constant low latency across both the short and long-duration videos.
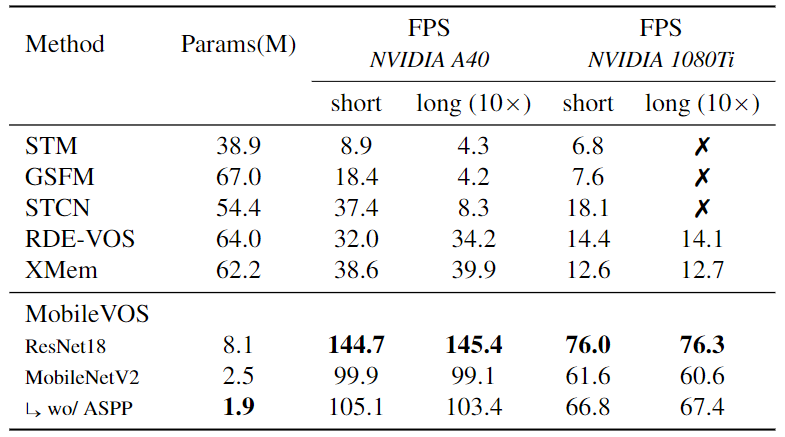
Table 2. Performance evaluation on the same sets of hardware. The short videos consist of 50 frames, while the long videos consist of 500. In all cases, we use the authors’ provided code and X indicates that the models are exceeding the GPU memory limit.
Qualitative Results
The following figure shows the segmentation of two identical models trained with and without knowledge distillation. In this example, we observe that the distilled model is able to successfully segment the panda despite undergoing drastically different views and occlusions. This observation confirms the original theoretical motivation that maximising the mutual information of representations between an infinite and finite memory models, implicitly encourages temporally robust features. Additional experiments on out-of-domain videos, image in-painting, and on-device segmentation can be found in the supplementary material.

Figure 4. Qualitative evaluation of our unified loss. Comparing the segmentation of two models with and without the joint and distillation loss being applied.
Conclusion
In this work, we present a simple loss that unifies knowledge distillation and contrastive learning. By applying this loss in the context of semi-supervised video object segmentation, we achieve competitive results with state-of-the-art at a fraction of the computational cost and model size. These models are compact enough to fit on a standard mobile device, while retaining real-time latency.
Link to the paper
https://arxiv.org/pdf/2303.07815.pdfReferences
[1] Ho Kei Cheng and Alexander G Schwing. “XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model”. In: ECCV (2022).
[2] Mingxing Li et al. “Recurrent Dynamic Embedding for Video Object Segmentation”. In: CVPR.
[3] Yongqing Liang et al. “Video Object Segmentation with Adaptive Feature Bank and Uncertain-Region Refinement”. In: NeurIPS. 2020.
[4] Yong Liu et al. “Global Spectral Filter Memory Network for Video Object Segmentation”. In: ECCV (2022).
[5] Seoung Wug Oh et al. “Space-time Memory Networks for Video Object Segmentation with User Guidance”. In: PAMI. 2020.
[6] Seoung Wug Oh et al. “Video object segmentation using space-time memory networks”. In: ICCV. 2019.
[7] Kai Xu and Angela Yao. “Accelerating Video Object Segmentation With Compressed Video”. In: CVPR. 2022.

