Security & Privacy
Automatically Explaining the Privacy Practices in Mobile Apps
Introduction: The need to improve transparency and consistency in mobile app privacy
Can you tell what personal data your mobile app collects and uses?
While many mobile applications persistently collect various data from users, it is generally unclear what information is collected and how this information is used. Privacy policies are intended to outline these details by disclosing in legal terms, the usage, management and collection of data. However, despite the original intent, it is largely unclear to the user in many instances, thus making it harder for the user to trust the application with his/her personal information. Some users may favor an application collecting certain personal information to offer better services, while others may be interested in targeted recommendations and offers personalized for the user.
However, still lacking are transparency and consistency over the purposes stated in the privacy policy and the actual execution within the application. This is the starting point for our research. We believe technology can help in transparency and consistency. Our work in collaboration with the University of Michigan, called ‘PurPliance’, automatically analyzes and compares statements in privacy policies with the actual execution in the application. This work is one of many efforts in our research to improve user privacy and increase digital responsibility.
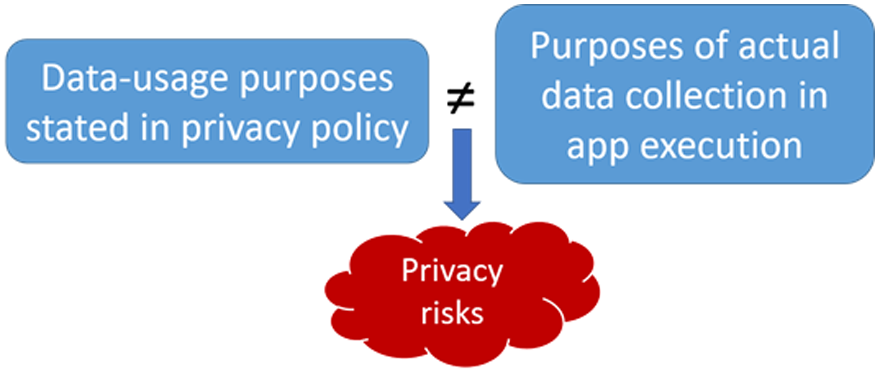
Figure 1. Inconsistency between user expectation and reality about purposes of data collection.
The current state of privacy policies
The privacy policy portrays to the user what, how and why an application collects the user’s personal data.
Currently, understanding a privacy policy is quite a challenge. For the application developer and policy-maker, who create the application and its corresponding privacy policy, it is difficult to draft a document that accurately depicts the application’s privacy practices. The developer and policy- maker may well have different levels of understanding about the application and the privacy policy. This gap makes it hard for the privacy policy to faithfully document the application’s execution and privacy practices.
The regulator also finds it difficult to understand the privacy policy because it is written in the complex legal language. While the regulator may attempt to examine the privacy policy to protect user rights, the opaque language used in the privacy policy evades clear understanding. Therefore, the regulator often cannot make clear judgement on the application following privacy regulation due to vagueness of the privacy policy.
Finally, the end user also finds it a daunting task to understand the privacy policy. It is extremely hard to fathom how the application handles the user’s personal information even after perusing multiple pages of the privacy policy full of statements about the application’s privacy practices.
Thus, it is our goal to use technology to automate this process so that we can help the consumer, developer, regulator and policy-maker better understand privacy policies and application behaviors.

Figure 2. PurPliance Overview

Figure 3. PurPliance system workflow.
PurPliance programmatically analyzes privacy policies with a focus on data usage purposes, that is, how user information collected by applications is used. PurPliance takes a privacy policy written in natural language and automatically breaks it down to a number of statements that describe the data practices, stating what information is collected and how it is used.
PurPliance largely consists of two different parts, one analyzing the privacy policy, the other examining the application behavior. The first part extracts the purposes of data collection from the privacy policy. PurPliance searches for sentences that describe data collection practices through privacy policies using a dictionary of verbs that we compiled empirically from randomly selected privacy sentences. Then, the collected sentences are parsed and semantics of each word is analyzed within the structure of the sentence (semantic analysis) to construct a data purpose clause. Purpose clauses are classified by matching patterns of n-grams using them. We use a purpose taxonomy that we created with 4 high-level categories (Production, Marketing, Legality, Other) which can further be broken down into low-level purposes.
The outcome of this privacy policy analysis are data purpose clauses. PurPliance converts these clauses to privacy statements, which contains information about data transfer, such as data receiver, data type and data usage purpose. For example, the clause “third parties collect device identifiers for their advertising purposes” has “third parties” as the data receiver, “device identifier” as data type, and “advertising” as data usage purpose. The conversion is necessary so that formal verification is possible when comparing data usage purposes with the findings from application analysis, which we will explain in the following section. The conversion from data purpose clauses to privacy statements utilizes various techniques including semantic role labeling, named entity recognition and keyword matching. In our survey of about 17k Android app policies, the most prevalent data purpose in privacy statements is “provide service”. Figure 4 shows the full distribution of purpose classes in the privacy statements and mobile application data flows.
Figure 4. Distribution of purpose classes in the privacy statements and data flows of mobile apps.
Constructing data flows from network data traffic
The other part of PurPliance analyzes applications to obtain data usage purposes. The application’s data usage purposes are to be compared with purposes stated in the privacy policy for consistency check, hence improving the governance of the privacy policy implemented in the application. PurPliance first collects application network data traffic using dynamic analysis techniques. Analysis of data traffic yields what information is sent from the application via network and to which address the information is sent. We can determine the data usage purpose from the data recipient’s address and other information from data.
PurPliance also creates data flows from the results of data traffic analysis. A data flow contains information about the recipient, the data type and the data usage purpose. We re-implemented a prior work and made improvements to the original approach, from which data types and purposes can be inferred from data content, destination and app description. Data purposes of the prior work have been adapted to our purpose taxonomy that we described earlier. In our survey of data flows of 17.1k Android apps, device information is the most popular data type. Figure 5 shows the distribution of data types in applications’ data flows.
Figure 5. Distribution of data types in apps' data flows.
Finding contradictions between the statement and actual data flow
From statements in the privacy policy and data flows extracted from network data traffic, PurPliance detects contradictions inside privacy policies and contradictions between the statement and the actual data flow. This allows us to check that privacy policies are written with no internal logic flaws and well represent the applications’ behavior.
We use provable techniques to detect these contradictions made possible by PurPliance’s programmatic analysis. We constructed a rich set of relationship tables between different purposes and data types, to deal with the various subtleties in wording.
PurPliance carries out two types of consistency analysis. It first looks for policy contradiction, namely contradicting statements within a privacy policy. Then, PurPliance conducts flow consistency analysis that searches for discrepancy between statements in a privacy policy and the application’s actual behavior.
Key findings
We conducted a survey of approximately 17k Android applications from Google Play Store. We found potential inconsistency between data flows and privacy statements in nearly 70% of these applications. This indicates prevalence of inconsistencies in mobile application data practices.
Below is the summary of numeric details for our experimental findings:
• Applications: 23k applications selected from Google Play Store
• 16.8k policies with 1.4M sentences; 1.7M network requests from 17.1k applications
• Policy contradiction: Found 29k potentially contradictory sentence pairs in 3.1k (18.14%) of the policies surveyed
• Flow-statement inconsistency: Found 95.1k (13.56%) potentially inconsistent data flows in 11.4k (69.66%) applications
Summary
While the privacy policy offers details about the privacy practices within an application, it is challenging to produce, govern, and consume the privacy policy. With PurPliance, we believe we have moved the needle towards improving transparency and consistency in a privacy policy. We believe our progress in this area will lead to productive dialogues with the end user, regulator, developer and policy-maker.
Details about the purpose taxonomy and consistency analysis can be found in the full paper.
Link to the paper
https://dl.acm.org/doi/10.1145/3460120.3484536
Reference
[1] https://searchcio.techtarget.com/news/252504997/Amazon-GDPR-fine-signals-expansion-of-regulatory-focus
[2] https://www.cnbc.com/2021/09/02/whatsapp-has-been-fined-267-million-for-breaching-eu-privacy-rules.html
[3] https://www.nytimes.com/wirecutter/blog/state-of-privacy-laws-in-us/
[4] https://techcrunch.com/2021/07/06/kill-the-standard-privacy-notice/
[5] Haojian Jin, Minyi Liu, Kevan Dodhia, Yuanchun Li, Gaurav Srivastava, Matthew Fredrikson, Yuvraj Agarwal, and Jason I. Hong. 2018. Why Are They Collecting My Data?: Inferring the Purposes of Network Traffic in Mobile Apps. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT ’18). doi: 10.1145/3287051