Samsung R&D Institute China-Nanjing at the 2025 ICCV Mars2 Workshop: Advancing Multimodal Reasoning in Real-World Scenarios
Multimodal reasoning is critical for diverse applications but faces limitations in real-world environments due to traditional closed-set models, which rely on fixed data distributions and predefined outputs. Modern large reasoning models (LRMs) address this by adopting flexible, instruction-driven frameworks, enabling them to tackle open-world tasks efficiently. These models, trained on large-scale, multi-source datasets, aim to robustly handle diverse reasoning tasks, intrinsically comprehend scenes, and adapt to physical realities.
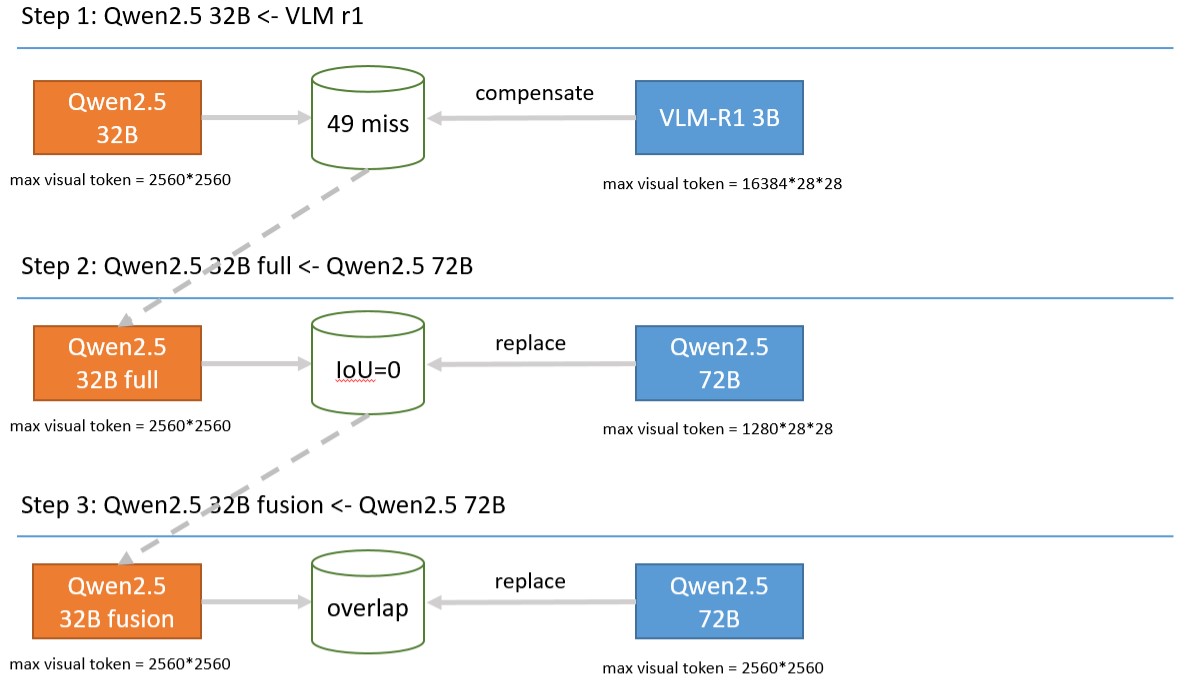
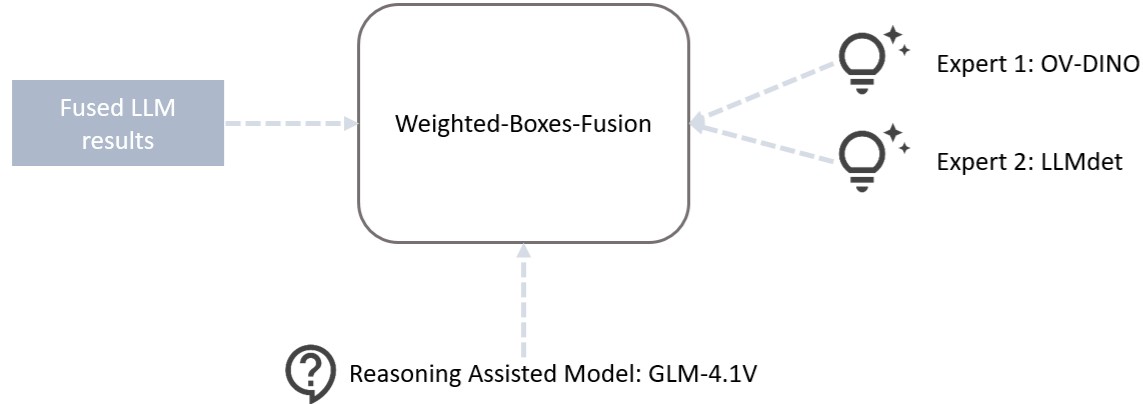
Samsung R&D Institute China-Nanjing(SRCN)-AIVL participated in the ‘ICCV Mars2 Workshop Multimodal Reasoning Competition’ in July 2025 to validate its understanding of LRMs. The competition featured multiple tracks, and the SRCN-AIVL team chose to participate in two tracks. The first track focused on real-world scenario visual grounding, evaluating the model's scene perception, object localization, and spatial reasoning abilities in complex multimodal scenarios. The second track focused on spatial-aware visual Q&A, assessing the model's capacity to perform spatial, commonsense, and counterfactual reasoning based on concrete physical content following user instructions. Both tasks required the model to understand the spatial relationships between objects in real-time scene photographs. To enhance existing multimodal reasoning models, the SRCN-AIVL participants focused on data pre-processing and post-processing, achieving results in both tracks.
In the real-world scenario grounding task, there were 20 participants, including ByteDance, JNU, NJUST, UCAS, and others. The SRCN-AIVL team secured fourth place in this track.
In the spatial-aware visual Q&A task, there were 14 participants, including Tele AI, ByteDance, HDU MILVLG, SUSTech, TUTE, and others. The SRCN-AIVL team secured fifth place in this track.