Samsung's New Video Frame Interpolation Technique Based on Transformer

Video Frame Interpolation (VFI) is a classic low-level vision task, which aims to increase the frame rate of videos by synthesizing non-existent intermediate frames between consecutive frames. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) is the top international computer vision conferences. A VFI paper (“Extracting Motion and Appearance via Inter-Frame Attention for Video Frame Interpolation”) co-worked by Intelligent Vision Lab of Samsung R&D Institute China-Nanjing (SRC-Nanjing) and Nanjing University has been recently accepted by CVPR 2023.
Intelligent Vision Lab of SRC-Nanjing
Intelligent Vision Lab (IVL) of SRC-Nanjing focuses on advanced computer vision technologies, including video frame interpolation, super resolution, style transfer, object detection, human pose understanding, etc. We have published several papers on top conferences and deployed some computer vision algorithms on Samsung’s products. We will keep going and make more contributions to Samsung.


Main Contributions of This Paper
This paper (“Extracting Motion and Appearance via Inter-Frame Attention for Video Frame Interpolation”) has the following main contributions.
1. It proposes a novel module to explicitly extract motion and appearance information via a unifying operation.
2. It designs a hybrid attention map from inter-frame which can be used both appearance feature enhancement and motion information extraction
3. It proposed a generalized module which could be seamlessly integrated into a hybrid CNN and Transformer architecture for efficient VFI, and also achieves state-of-the-art performance on various datasets for both fixed- and arbitrary-timestep interpolation

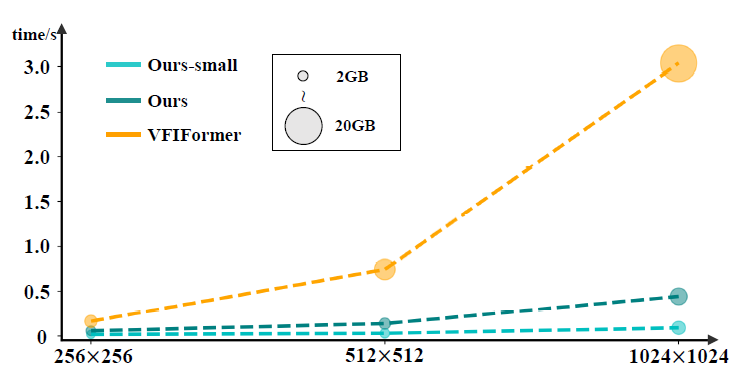
Quantitative Results
The proposed algorithm achieves excellent quantitative results (measured by PSNR and SSIM) on various video frame interpolation benchmarks. In particular, it get state if art performance with less model size and memory costing

Qualitative Results
The proposed algorithm is robust to large motion and complex non-linear motion cases. It gives better qualitative results on Vimeo90K benchmark than state-of-the-art methods.